文件欺骗仍然是攻击者用来绕过传统安全控制的最有效技术之一。去年,OPSWAT 推出了人工智能增强型文件类型检测引擎,弥补了传统工具的不足。今年,我们推出了文件类型检测模型 v3,将重点放在准确性最重要的文件类型上,从而提高了这一能力。
OPSWAT 文件类型检测模型 v3 设计用于解决模糊和非结构化文件的可靠分类这一特定挑战,尤其是基于文本格式的文件,如脚本、配置文件和源代码。与通用分类器不同,该模型是专为网络安全用例而设计的,在网络安全用例中,错误分类 shell 脚本或无法检测到包含嵌入式宏的文件(如带有 VBA 代码的 Word 文件)都会带来重大的安全风险。
为什么真正的文件类型检测至关重要
大多数检测系统依赖于三种常见方法:
- 文件扩展名:该方法检查文件名,根据扩展名(如 .doc 或 .exe)确定文件类型。这种方法速度快,而且广泛兼容各种平台。不过,它很容易被操纵。恶意文件可以用看起来安全的扩展名重命名,有些系统会完全忽略扩展名,因此这种方法并不可靠。
- 神奇字节:这是许多结构化文件(如 PDF 或图像)开头的固定序列。与文件扩展名相比,这种方法通过检查实际文件内容提高了准确性。缺点是并非所有文件类型都有定义明确的字节模式。魔术字节也可能被伪造,而且不同工具的标准不一致可能导致混淆。
- 字符分布分析:这种方法通过分析文件的实际内容来推断其类型。它尤其有助于识别结构松散的文本格式,如脚本或配置文件。虽然它能提供更深入的洞察力,但处理成本较高,而且可能会对异常内容产生误报。对于缺乏可读字符模式的二进制文件,这种方法也不太有效。
这些方法对结构化格式很有效,但应用于非结构化或基于文本的文件时就变得不可靠了。例如,包含最少命令的 shell 脚本可能与纯文本文件非常相似。许多此类文件都缺乏强大的标题或一致的标记,因此基于字节模式或扩展名的分类方法是不够的。攻击者利用这种模糊性将恶意脚本伪装成无害文档或日志。
TrID 和 LibMagic 等传统工具并不是为这种细微差别而设计的。虽然它们对一般文件分类很有效,但它们是为广度和速度而优化的,而不是为安全限制下的专门检测而优化的。
文件类型检测模型 v3 的工作原理
文件类型检测模型 v3 的训练过程包括两个阶段。在第一阶段,使用屏蔽语言建模(MLM)进行领域适应性预训练,让模型学习特定领域的语法和结构模式。在第二阶段,模型在有监督的数据集上进行微调,其中每个文件都明确标注了其真正的文件类型。
该数据集由常规文件和威胁样本精心组合而成,确保在现实世界的准确性和安全相关性之间取得很好的平衡。OPSWAT 可对训练数据进行控制,从而不断改进对安全操作最重要的格式。
人工智能组件的应用精准而不宽泛。文件类型检测模型 v3 专注于传统检测方法无法有效处理的模糊和非结构化文件类型,如脚本、日志和结构不一致或不存在的松散格式文本。平均推理时间保持在 50 毫秒以下,使其在安全文件上传、端点执行和自动化管道的实时工作流中非常高效。
基准结果
我们使用一个大型、多样化的数据集,将OPSWAT 文件类型检测引擎与领先的文件类型检测工具进行了基准测试。比较包括 248,000 个文件和约 100 种文件类型的 F1 分数。
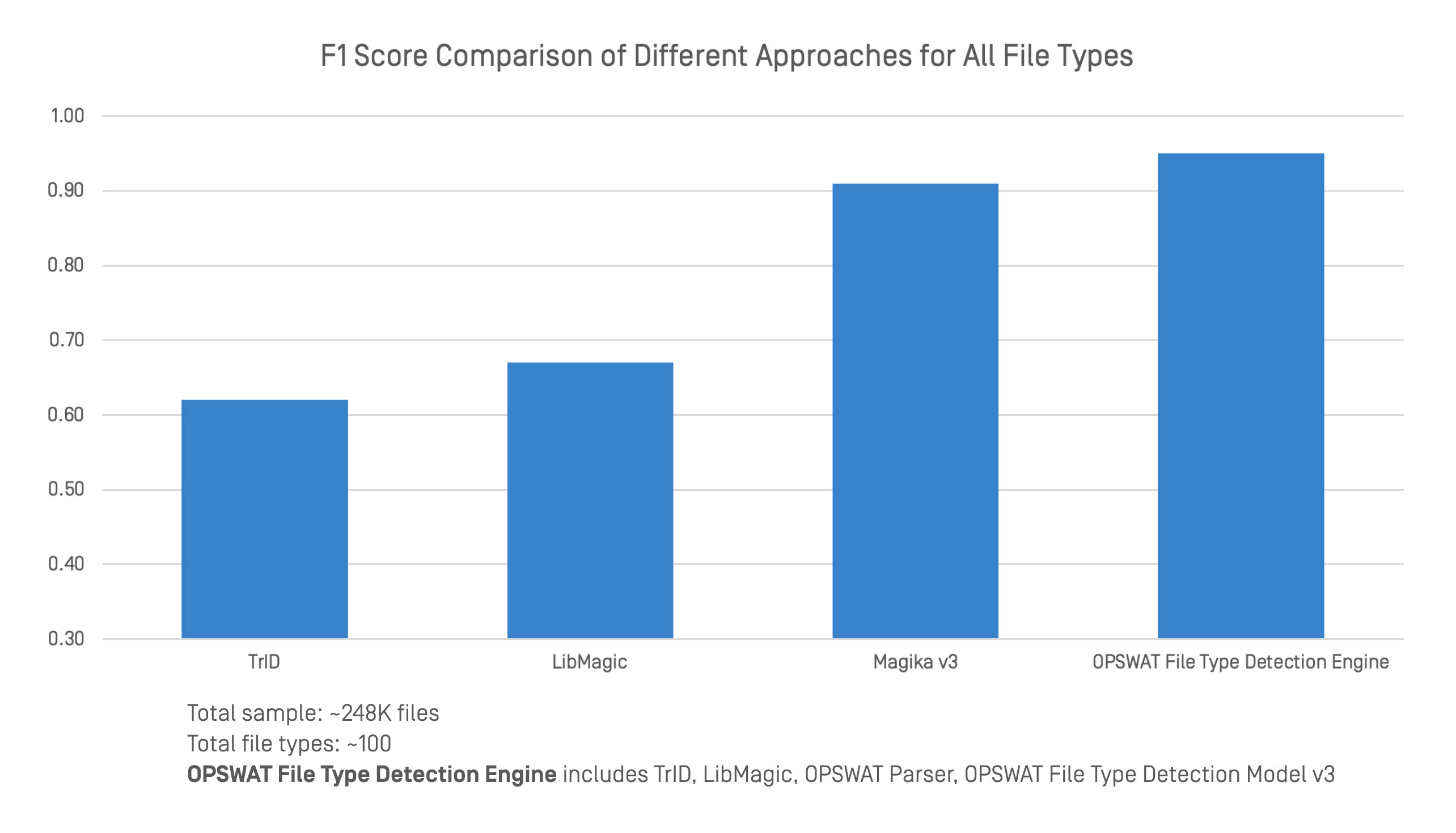
OPSWAT 文件类型检测引擎集成了多种技术,包括 TrID、LibMagic 和OPSWAT自身的技术(如高级解析器和文件类型检测模型 v3)。 这种组合方法可为结构化和非结构化格式提供更强大、更可靠的分类。
在基准测试中,该引擎的总体准确率高于任何单独的工具。虽然 TrID、LibMagic 和 Magika v3 在某些方面表现出色,但当文件头丢失或内容含糊不清时,它们的准确性就会下降。通过将传统检测与深度内容分析相结合,OPSWAT 即使在结构薄弱或有意误导的情况下也能保持稳定的性能。
文本和脚本文件
基于文本和脚本的格式经常涉及文件传播威胁和横向移动。我们对 169,000 个文件进行了重点测试,这些文件格式包括 .sh、.py、.ps1、 和 .conf.
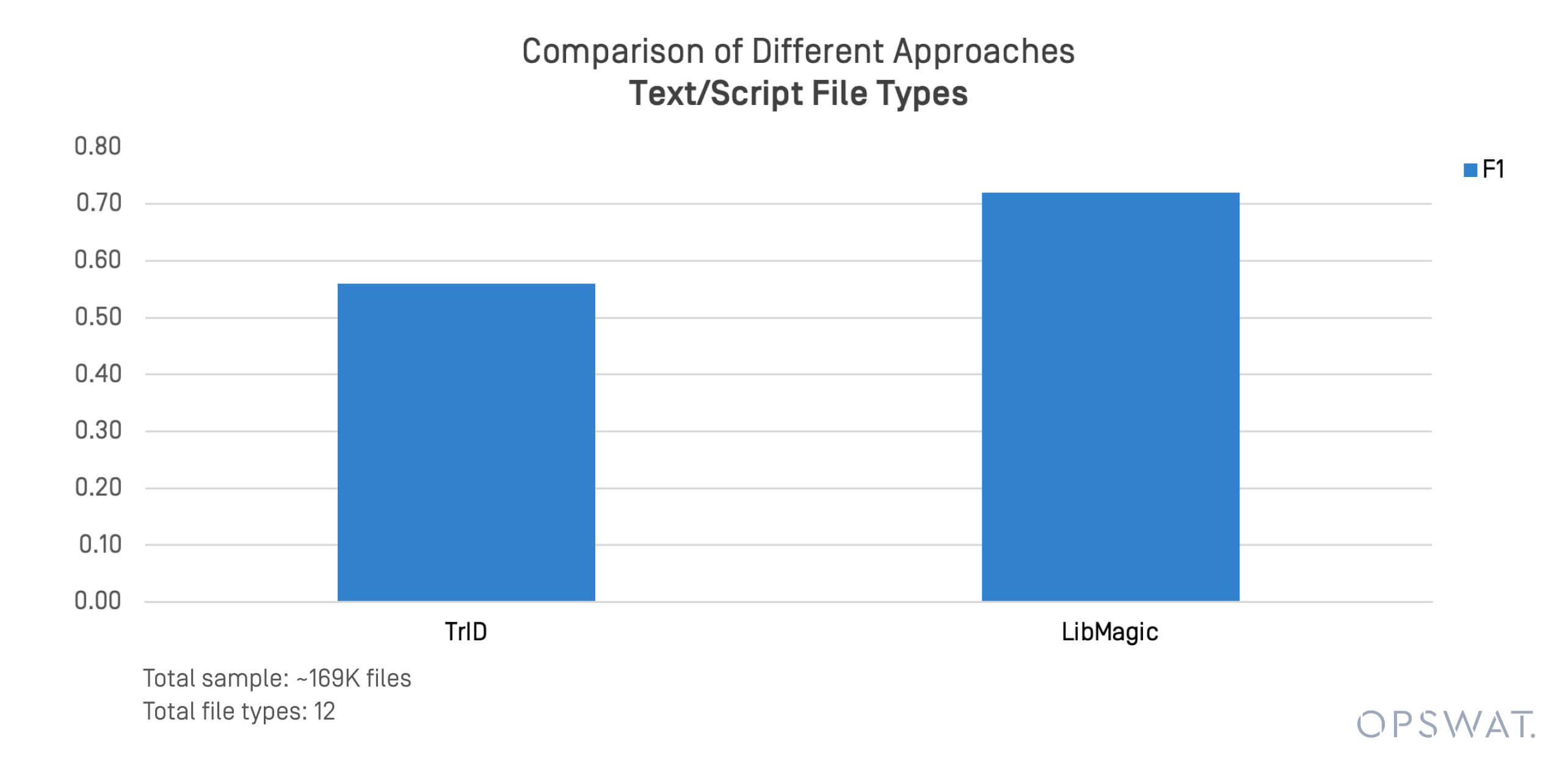
TrID 和 LibMagic 在检测这些非结构化文件时表现出了局限性。当文件内容偏离预期的字节模式时,它们的性能会迅速下降。
文件类型检测模型 v3 vs Magika v3
我们使用相同的 500,000 个文件数据集,针对 30 种文本和脚本文件类型,对OPSWAT 文件类型检测模型 v3 和谷歌开源人工智能分类器 Magika v3 进行了评估。
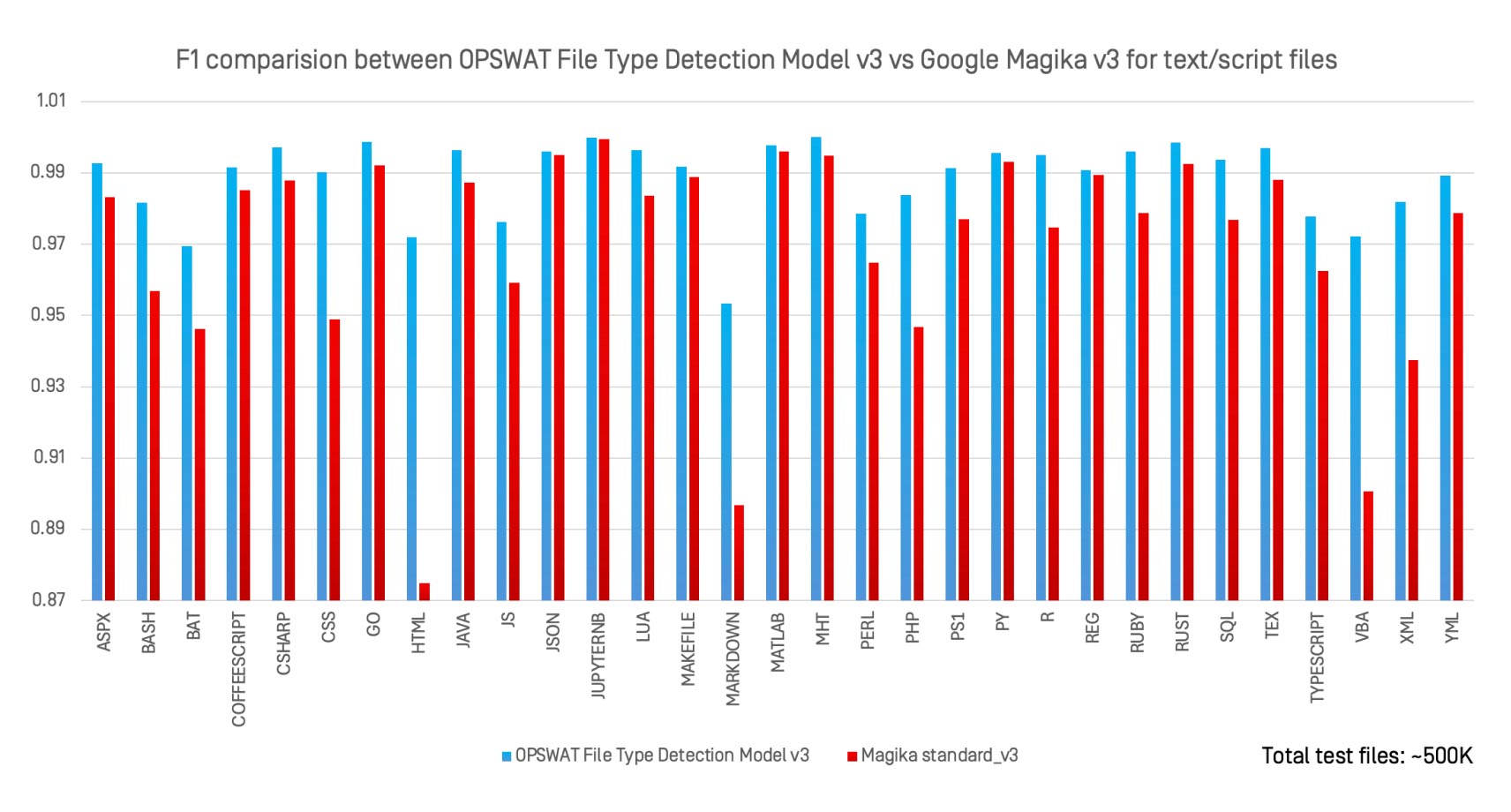
主要意见:
- 文件类型检测模型 v3 在几乎所有格式上的表现都与 Magika 不相上下,甚至更胜一筹。
- 涨幅最大的是松散定义的格式,如
.bat、.perl、.html、和 。xml. - 与专为通用识别而设计的 Magika 不同,文件类型检测模型 v3 专门针对高风险格式进行了优化,在这些格式中,错误分类会产生严重的安全影响。
顶级使用案例
Secure 上传、下载和传输文件
防止伪装或恶意文件通过门户网站、电子邮件附件或文件传输系统进入您的环境。人工智能增强型检测功能超越了扩展名和 MIME 标头,可识别重命名文件中的脚本、宏或嵌入式可执行文件。
DevSecOps 管道
在不安全的工件污染您的软件构建或部署环境之前阻止它们。通过根据实际内容验证真实文件类型,MetaDefender Core 可确保只有经过批准的格式才能通过 CI/CD 管道,从而降低供应链攻击的风险,并保持安全开发实践的合规性。
合规执行
准确的文件类型检测对于满足 HIPAA、PCI DSS、GDPR 和 NIST 800-53 等法规要求至关重要,这些法规要求对数据完整性和系统安全性进行严格控制。检测和阻止欺骗或未经授权的文件类型有助于执行政策,防止敏感数据泄露,保持审计准备就绪,避免代价高昂的处罚。
最终想法
Magika 等通用文件分类器对于广泛的内容分类非常有用。但在网络安全领域,精度比覆盖面更重要。一个被错误分类的脚本或被错误标记的宏可能就是控制与入侵之间的差别。
OPSWAT 文件类型检测引擎提供了这种精确性。通过将人工智能增强型文件类型分析与成熟的检测方法相结合,它能在传统工具失效的情况下提供可靠的分类层,尤其是在模棱两可或非结构化格式的情况下。这并不是要取代一切,而是要通过实时、上下文感知检测来加强安全堆栈中的关键薄弱点。

