随着数据隐私、安全和高效资源分配的重要性日益增加,文件类型检测是企业面临的一项关键挑战,但却常常被忽视。人工智能(AI)正在彻底改变文件类型验证(MetaDefender Platform 的核心组件),因为它可以利用机器学习检测欺骗文件。与传统的静态扫描解决方案相比,这不仅提高了检测的准确性,还大大提高了运行效率。
文件类型欺骗技术
虽然更改文件扩展名(如将 .exe 改为 .txt)在过去是一种常见的策略,但安全解决方案已越来越善于识别此类基本技巧。这使得攻击者开始使用更复杂的方法。现代文件类型欺骗已超出了简单的扩展名操作。攻击者可以操纵文件的内部结构来模仿合法的文件类型。
攻击者面临的真正挑战不仅在于伪装文件,还在于欺骗用户执行文件。社会工程学策略往往在这里发挥作用。攻击者可能会用熟悉的图标或名称伪装文件,诱使用户打开。或者,他们可能会利用软件中的漏洞,使文件无论被认为是什么类型都能自动执行。
在某些情况下,欺骗文件甚至可能是精心策划的多阶段攻击的一部分。一个看似无害的文件可能会在目标系统上下载或安装真正的恶意有效载荷。
文件类型欺骗具有很大的风险,因为它绕过了传统的基于签名的检测方法,而这种方法依赖于预先定义的恶意代码模式。这种欺骗技术可用于传播各种威胁,包括勒索软件、木马和蠕虫。
为什么准确的文件类型检测很重要
文件过滤是组织安全的基石。通过准确识别文件类型,组织可以有效阻止恶意文件。这样既能防范恶意软件等入站威胁,又能防止敏感信息外流,从而提高隐私保护。此外,过滤掉娱乐媒体等非必要文件还能优化资源利用率。这一点在医疗保健领域尤为重要,因为 HIPAA 法规要求加强患者数据保护,以保护数字医疗保健数据免受网络攻击。可靠的文件类型检测是成功实现文件过滤合规性的基础。
文件类型检测的重要性不仅限于文件过滤。病毒扫描程序通常利用它来确定扫描的优先级。通过有效识别历史上与病毒无关的文件类型,扫描程序可以将资源集中在高风险文件上,加快恶意威胁的检测速度。
准确的文件类型检测在各种安全和数据管理实践中发挥着至关重要的幕后作用,包括




文件验证的三种主要方法
| 方法 | 优点 | 缺点 |
| 文件扩展名 | 快速简便:检查文件扩展名,快速识别。 普遍适用于大多数操作系统。 | 容易受骗:攻击者可以简单地用无害的扩展名重命名恶意文件。 对于非标准扩展名有限制,对于扩展名可有可无的 Linux/Unix 则不可靠。 |
| 神奇字节 | 更可靠:依靠特定字节模式(神奇字节)进行识别,比扩展名更准确。可以识别没有扩展名的二进制文件。 | 覆盖范围有限:只适用于定义了神奇字节的文件类型。并非所有文件类型都有。容易被攻击者篡改魔法字节进行欺骗。不同来源的信息不一致会造成混乱。 |
| 字符分布分析 | 揭穿欺骗:分析实际内容以揭示真实的文件类型,从而揭露隐藏在无害扩展名下的恶意软件。提供有关文本文件类型(如纯文本与代码)的宝贵见解。 | 计算成本高:需要读取和分析文件内容,因此速度比其他方法慢。对于独特或不规则的文件内容,可能出现错误警报。对缺乏明显字符分布的二进制文件效果有限。 |
OPSWAT 如何利用人工智能准确检测文件类型
为了提高准确性和安全性,OPSWAT File Type Verification 技术超越了这些传统方法,利用 MetaDefender Core的工作流程,将它们组合成一个功能强大、效率独特的过滤流程。它缩短了处理时间,同时实现了尽可能高的准确性。
最近,我们还专门增加了机器学习检测功能,以应对基于文本文件的挑战。这些文件(如日志文件、脚本文件和自述文件)都是简单的 "文本",缺乏其他方法所显示的明显特征。分析其内容对于准确分类至关重要。对文本文件的错误分类可能会带来危险,因为恶意脚本文件可能会在未被发现的情况下运行。
在MetaDefender Core 中配置基于文本的文件类型验证。
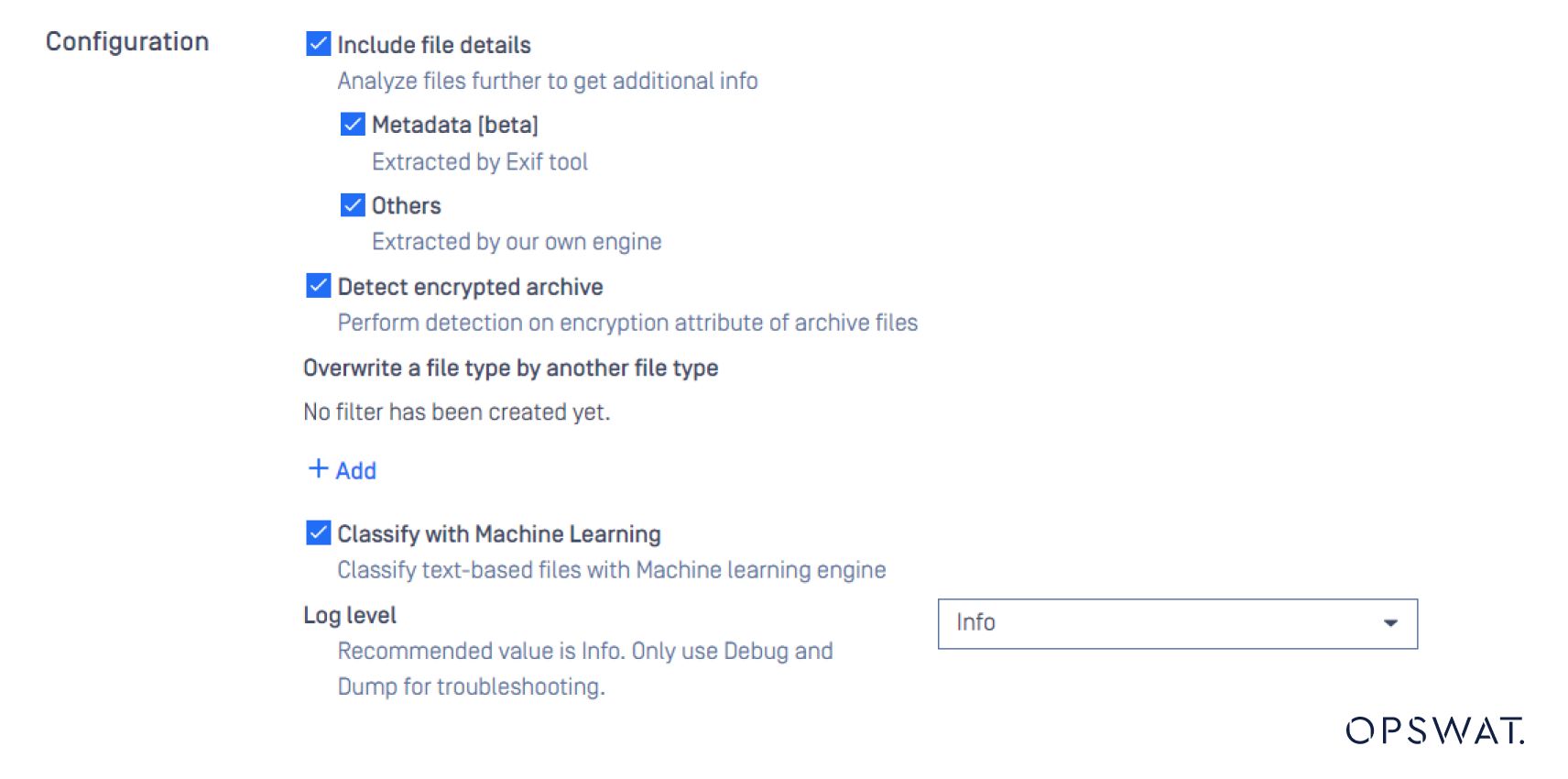
让我们看看这个例子,看看它是如何工作的。
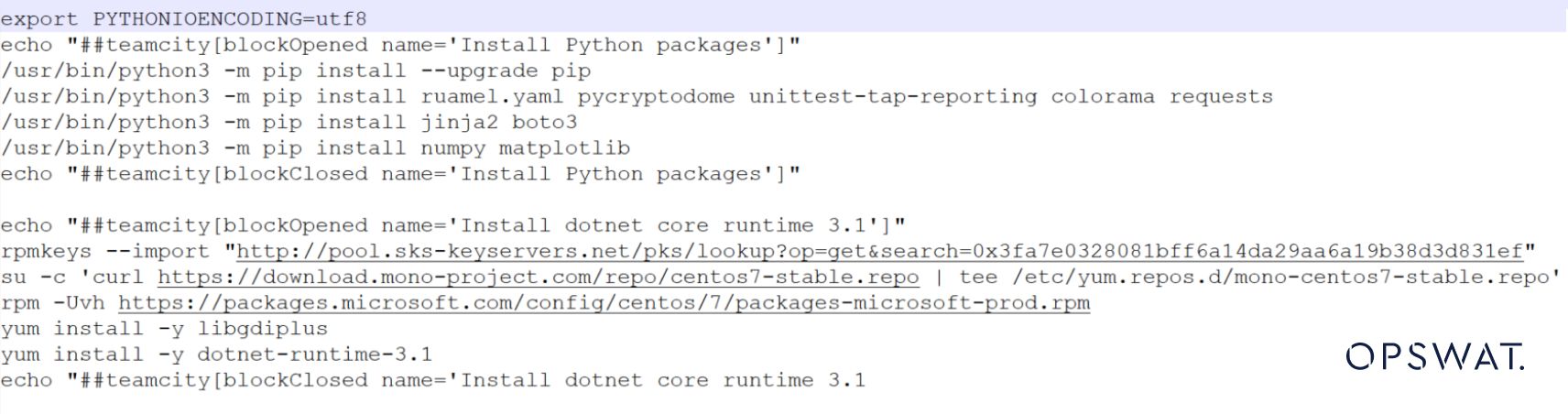
请看有人工智能和没有人工智能在检测文件类型方面的对比。
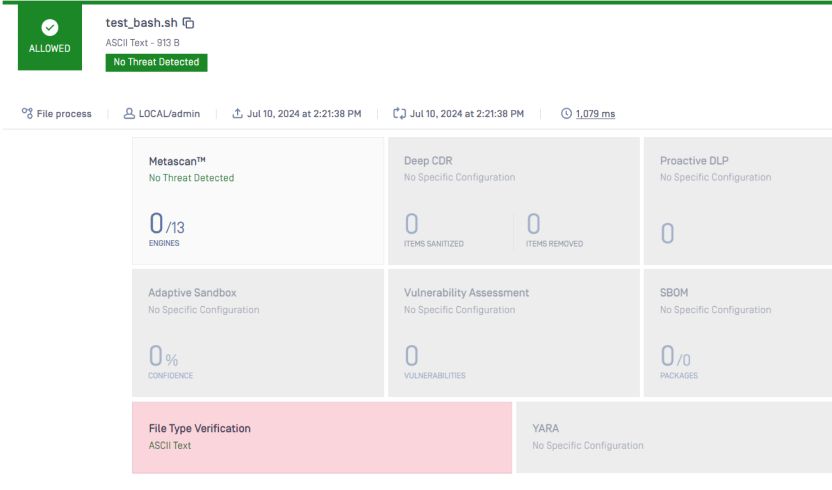
有趣的是,我们可以修改 shell 文件,在顶部添加简短说明,如下图所示。
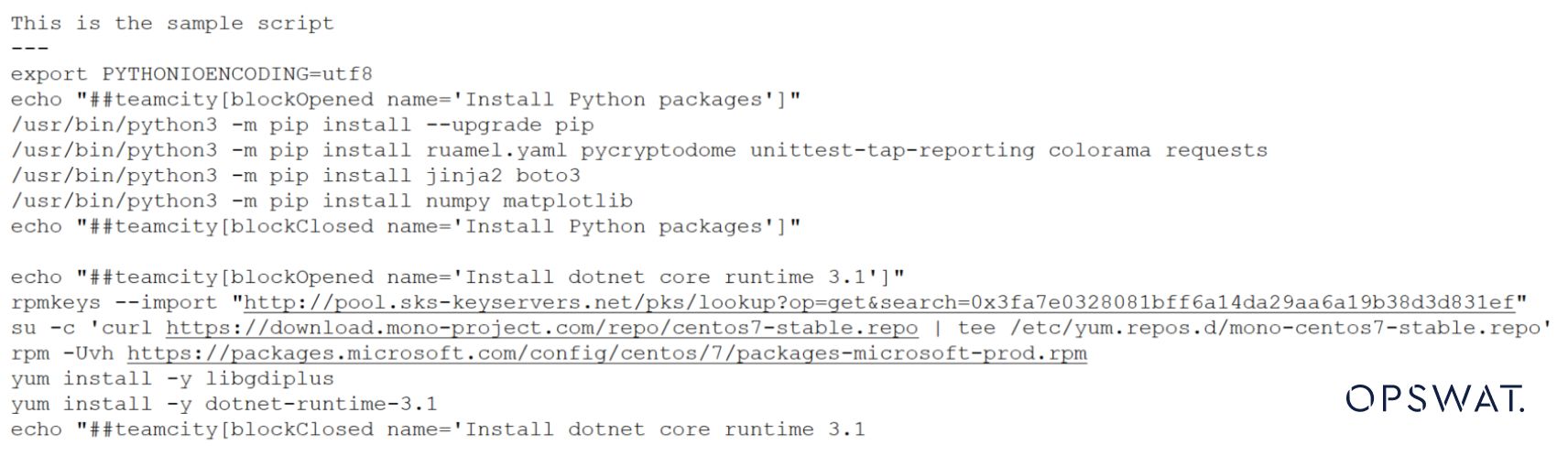
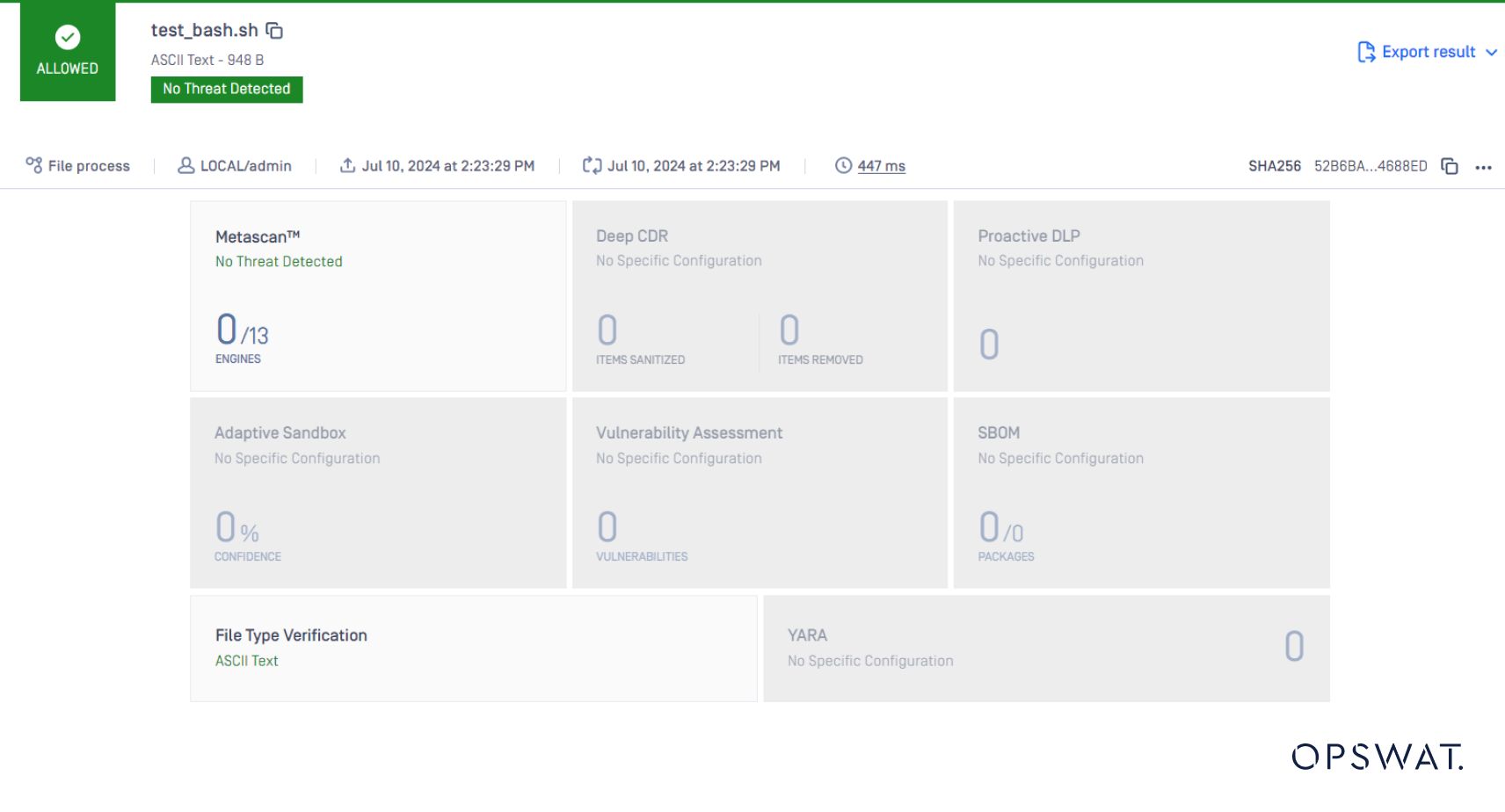
文件类型会再次将其检测为文本,这是正确的。它不再是脚本。
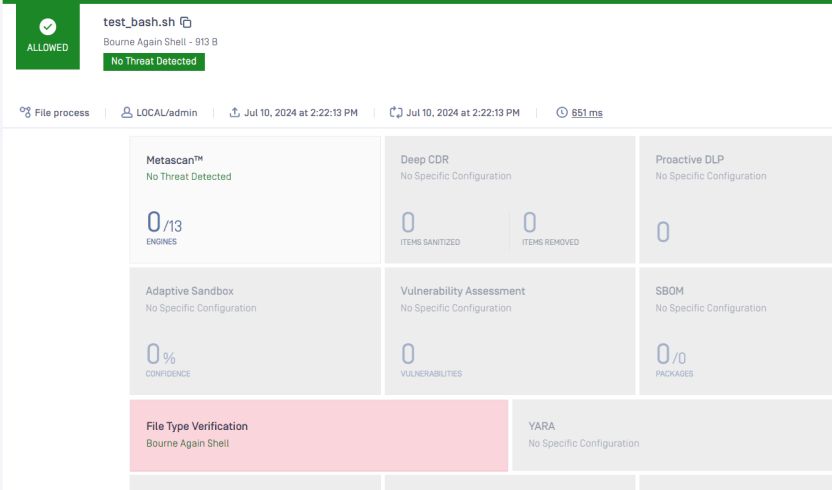
如果我们注释掉这两行,但仍然保留它,如下图所示。
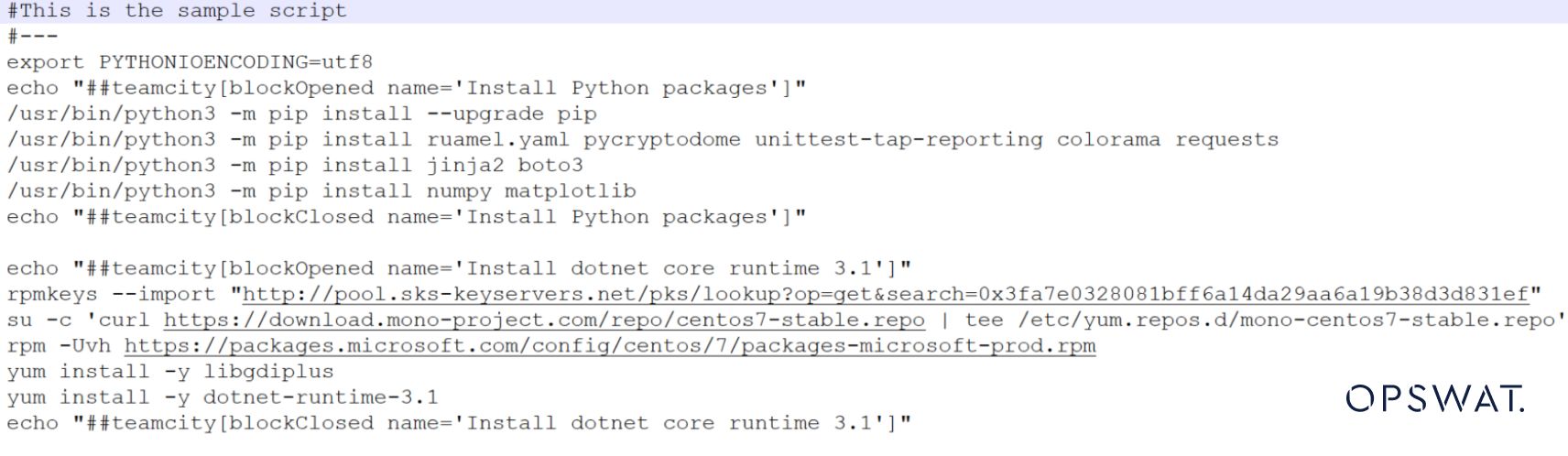
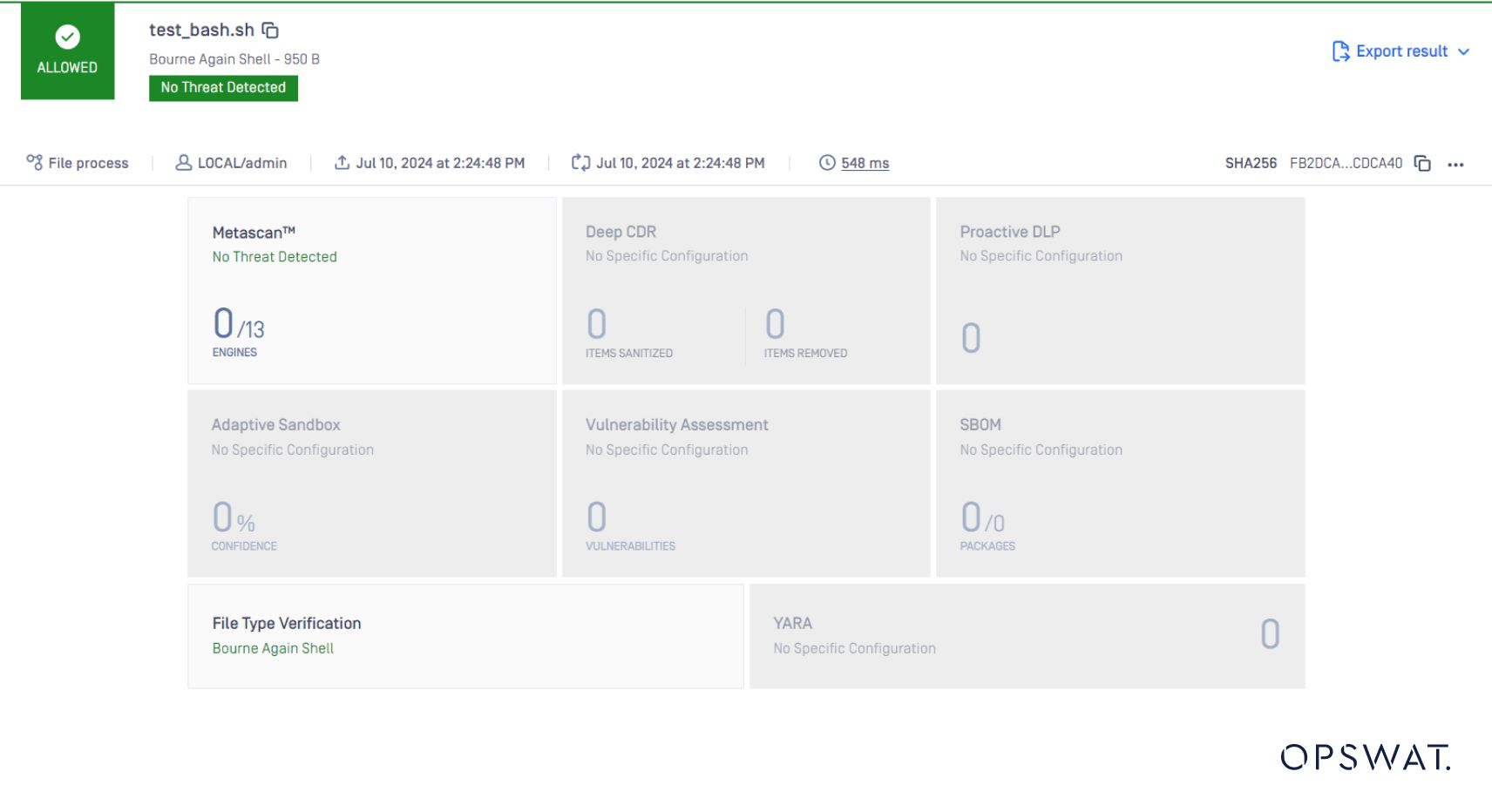
文件类型应为
通过利用深度学习进行基于文本的文件分析,OPSWAT File Type Verification :
- 更高的准确性--人工智能模型甚至可以识别最复杂的文件类型欺骗企图,尤其是基于文本的文件。
- 面向未来的安全性 - 适应新威胁的能力可确保持续保护。
- 提高效率 - 准确的检测减少了人工分析的需要,节省了时间和资源。
结束语
虽然准确的文件类型检测构成了关键的第一道防线,但OPSWAT File Type Verification 的人工智能增强功能使企业能够进一步加强其安全态势。通过将这一先进的解决方案与其他安全措施(如文件传播恶意软件预防和敏感数据保护)结合使用,企业可以实现多层防御,保护其组织免受文件类型欺骗威胁和数据泄露。
如需了解更多信息,请咨询我们的网络安全专家。

