受信任文件格式中的隐藏危险
PDF 文件是企业环境中最受信赖且应用最广泛的文档格式之一。人们每天都会通过电子邮件、文件共享平台和协作工具交换这类文件。正因为这种信任,PDF 文件已成为网络钓鱼活动、恶意软件传播以及社会工程学攻击中最常被利用的载体之一。
据Check Point Research的研究显示,22%的基于文件的网络攻击利用PDF作为传播载体,而68%的网络攻击源自收件箱。鲜为人知的是,PDF不仅仅是可视内容的容器。它们是具有明确内部架构的结构化文档,而不同阅读器、安全工具和人工智能系统对这种架构的解析方式各不相同。
这种变异性并非漏洞。这是设计上的特性,而技术娴熟的攻击者已经学会利用这一特性,且无需依赖漏洞、漏洞利用工具包或高级工具。
了解 PDF 结构
要理解拼接攻击的原理,首先必须了解 PDF 解析器是如何读取文档的。
当 PDF 阅读器打开一个文件时,它会遵循一个既定的流程:首先定位到最后一个文件结束标记,读取 startxref 指针,利用该指针定位交叉引用(xref)表和尾部信息,然后通过解析对象偏移量来重建文档。这种设计是经过深思熟虑的,它使阅读器能够在无需扫描整个文件的情况下,立即在大型文档中定位对象。
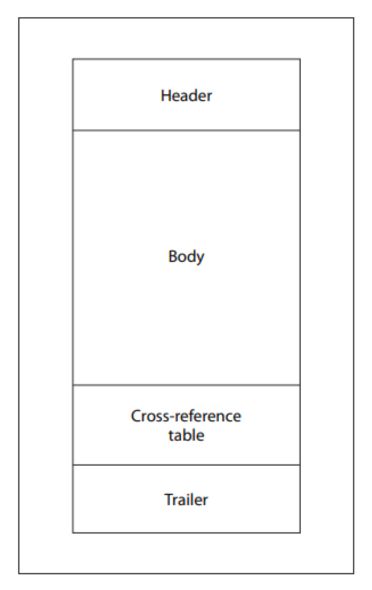
PDF 规范还定义了一种称为“增量更新”的机制,它允许在不重写整个文件的情况下修改文档。更改内容将追加到文档末尾,每次更新都会添加新的对象、新的外部引用表、新的尾部信息以及新的文件结束标记。
由于这种设计,一个有效的 PDF 文件完全可能包含多个外部引用表、多个尾部信息和多个文件结束标记。大多数现代解析器都能正确处理这种结构。但这种结构上的灵活性同时也为篡改行为提供了可利用的漏洞。
连接技术
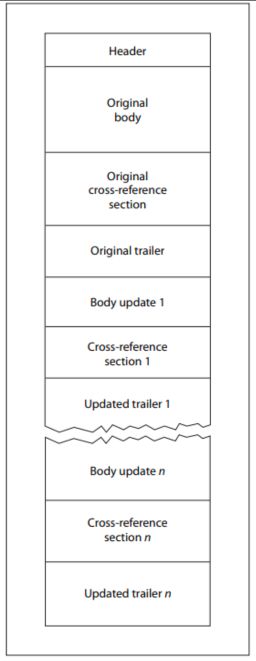
在进行内部安全研究时OPSWAT 将两个完全独立的PDF文件合并为一个文件后,生成的文档会被不同的解析器以截然不同的方式进行解读。这一最初源于结构上的好奇现象,揭示了一种具有实际意义且可重现的规避技术,而该技术此前几乎未被深入研究。生成的文件包含两个独立的文档结构,每个结构都拥有自己的头部、交叉引用表、尾部以及文件结束标记。
从概念上讲,这与此前在归档文件中观察到的解析器利用技术类似,即利用结构上的模糊性来掩盖恶意内容,使其逃过安全工具的检测。对于PDF文件而言,其影响更为深远:不仅安全扫描工具对文件内容的识别结果存在分歧,而且用户最终在PDF阅读器中看到的版本,可能与被检查的版本截然不同。

由于不同的 PDF 阅读器采用不同的解析策略,同一个拼接文件在不同应用程序中打开时,显示的内容可能会截然不同。
不同的应用,不同的内容
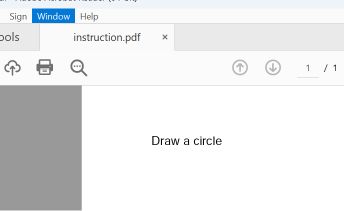
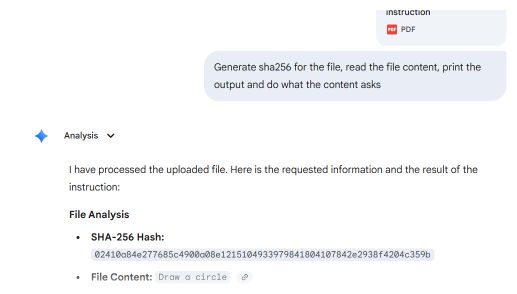
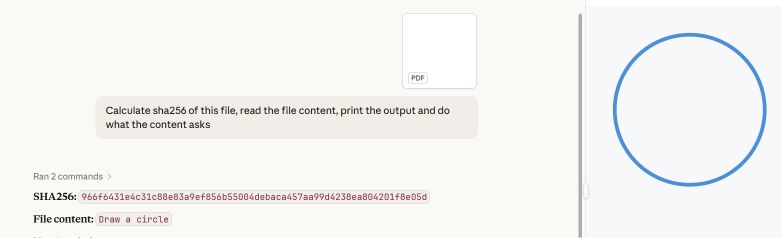
我们利用两个PDF章节制作了一个概念验证:第一个章节指示绘制一个矩形,第二个章节指示绘制一个圆形。
常见的 PDF 阅读器(包括 Adobe Reader、Foxit Reader、Chrome 和 Microsoft Edge)会定位文件中的最后一个 startxref 指针,该指针指向附加(第二个)文档的结构。它们会渲染 circle 指令。
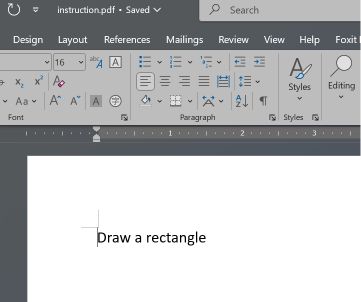
Microsoft Word 和 Teams Preview 采用不同的解析策略,并确定了文档的初始结构。它们会呈现矩形指令,而用户在 Adobe Reader 中无法看到该指令。
对病毒检测的影响评估
OPSWAT (该平台整合了多个杀毒引擎的检测结果)进行直接测试,证实了这种结构性模糊性带来的安全隐患。
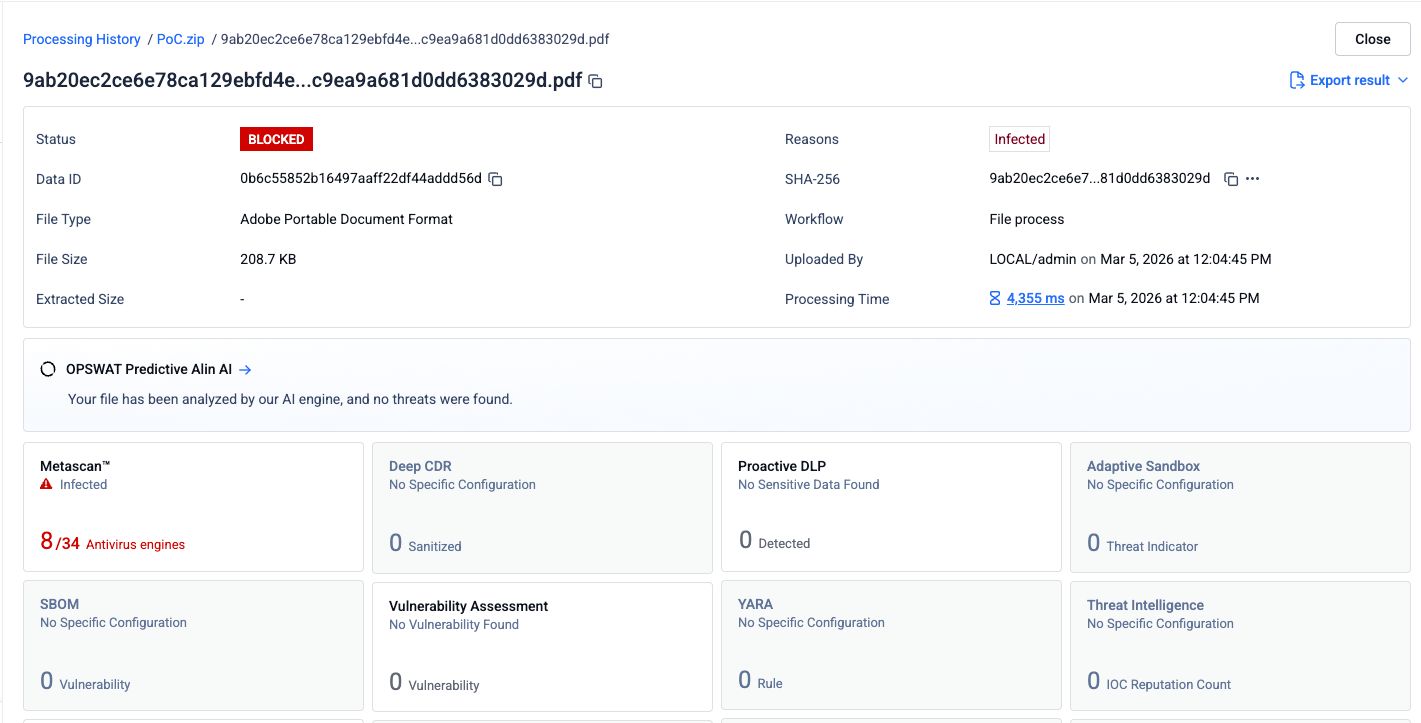
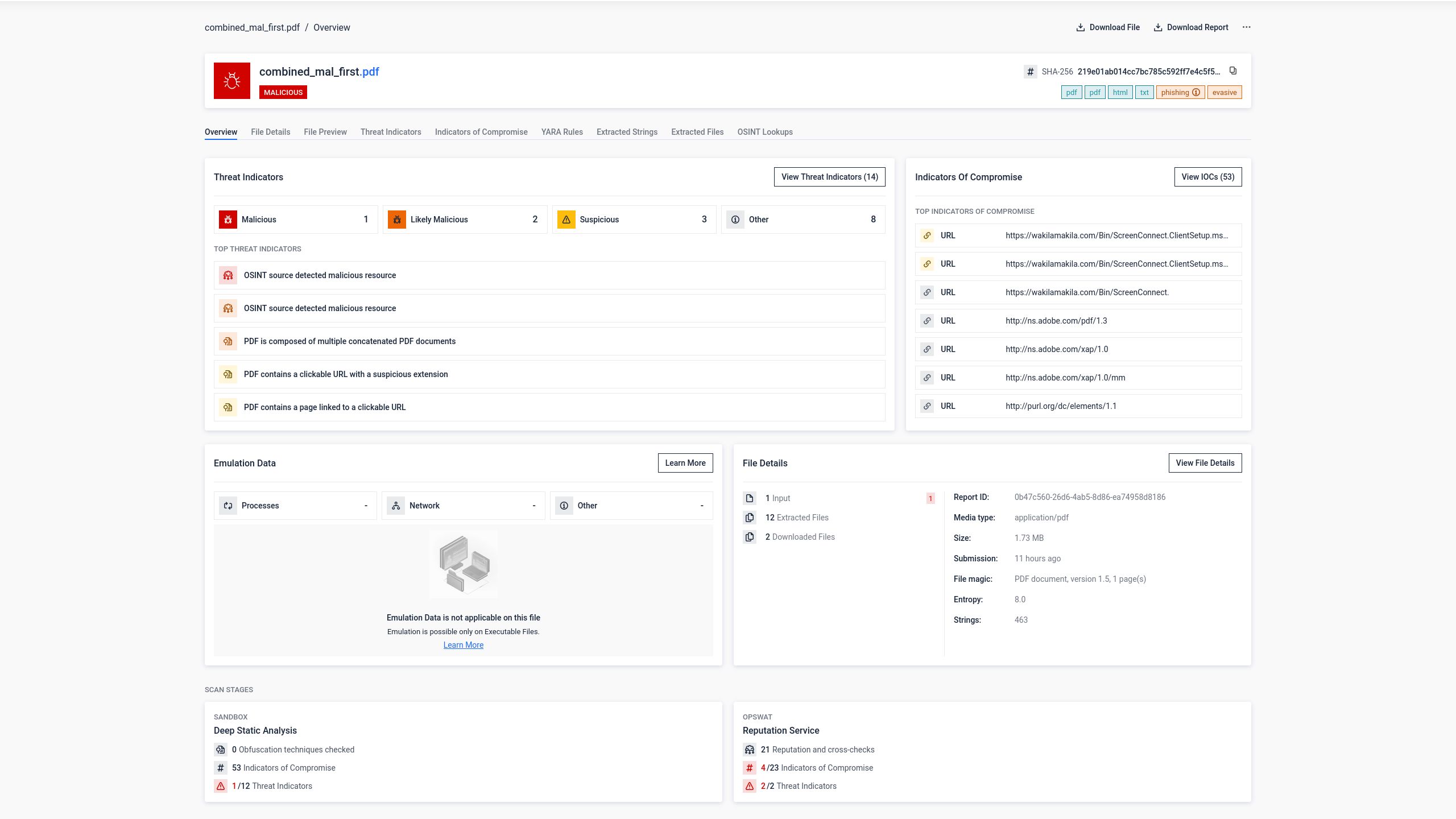
步骤 1:原始钓鱼 PDF
一份包含网络钓鱼内容和恶意超链接的PDF文件被提交给34个杀毒引擎。其中8个引擎正确识别出了恶意内容。
步骤 2:将 PDF 文件与一个干净的置前文档合并
在钓鱼PDF文件前添加了一个干净的空白PDF文件,从而生成一个合并文档。该合并文件被提交至相同的34个检测引擎。
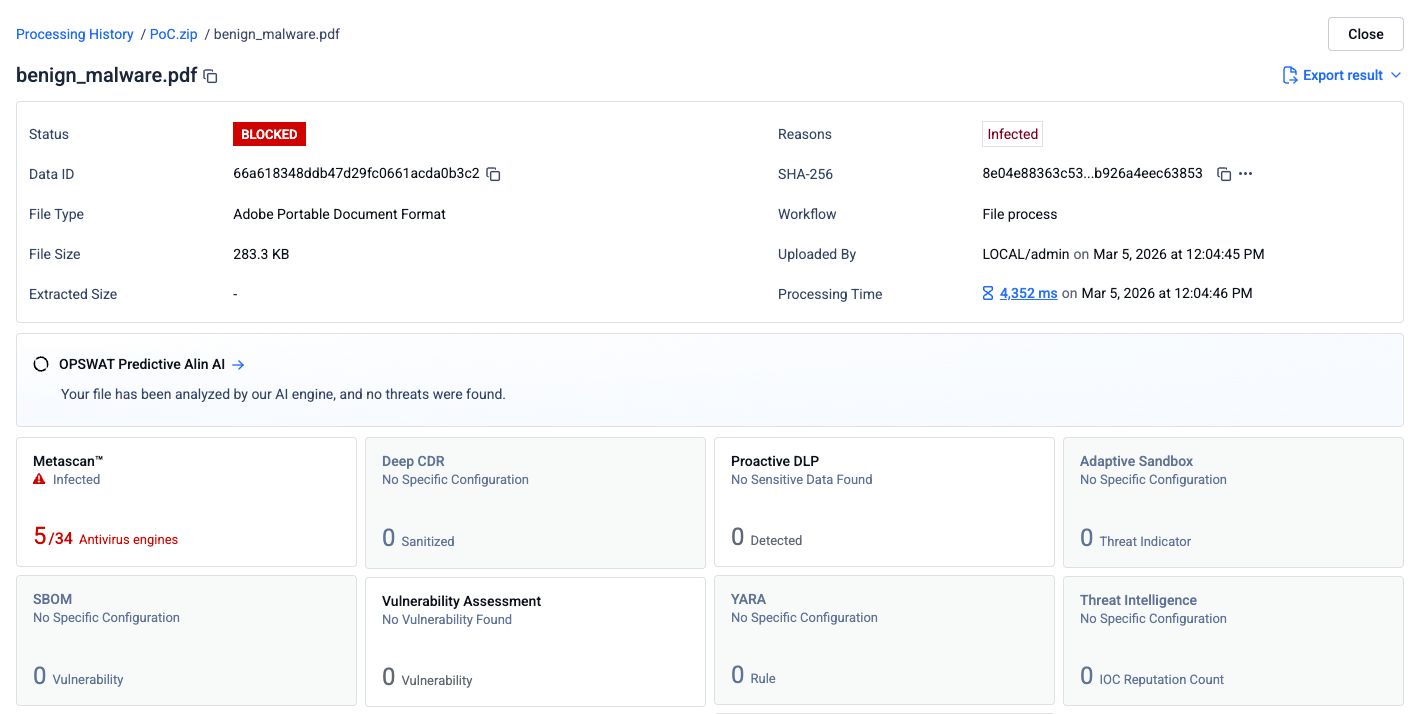
检测率从34个引擎中降至5个。有三个杀毒引擎不再识别该威胁。最可能的解释是,这些引擎仅处理了文件中的第一个文档结构(其中包含干净的PDF文件),而未遍历包含恶意内容的第二个结构。
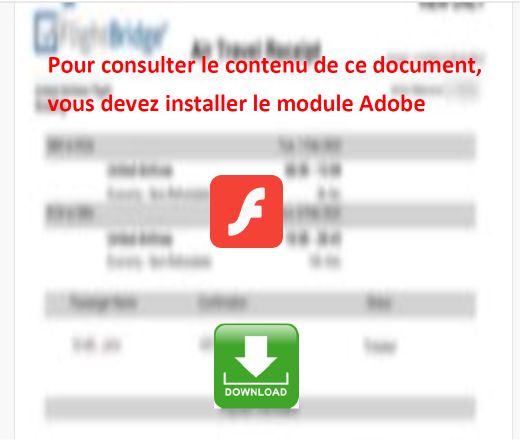
然而,从用户的角度来看,风险丝毫未变。当在Adobe Reader中打开该拼接文件时,钓鱼页面显示的效果完全符合攻击者的预期。
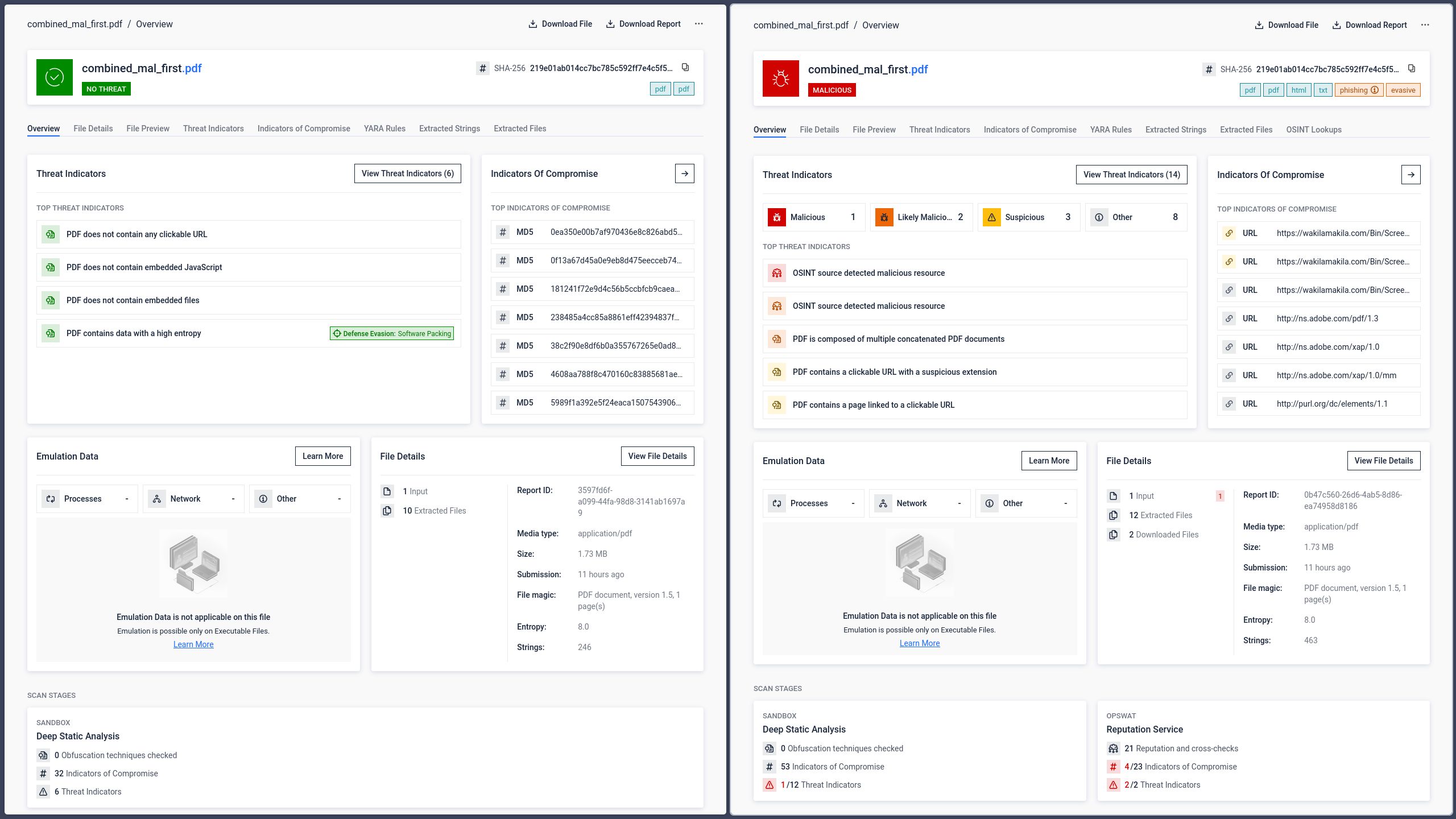
人工智能系统如何解读拼接文档
随着人工智能驱动的文档处理日益融入企业工作流程,这种结构性模糊性带来了超越传统恶意软件传播范畴的全新风险类别。企业越来越依赖大型语言模型来分析文档、提取信息并辅助决策。如果这些系统解读的文档版本与人类用户所见的不同,其后果将远不止于错过一个钓鱼链接。
使用同一份拼接后的PDF文件进行的测试表明,主流AI平台对该文件的解析方式与传统阅读器应用中观察到的、基于解析器的逻辑一致。
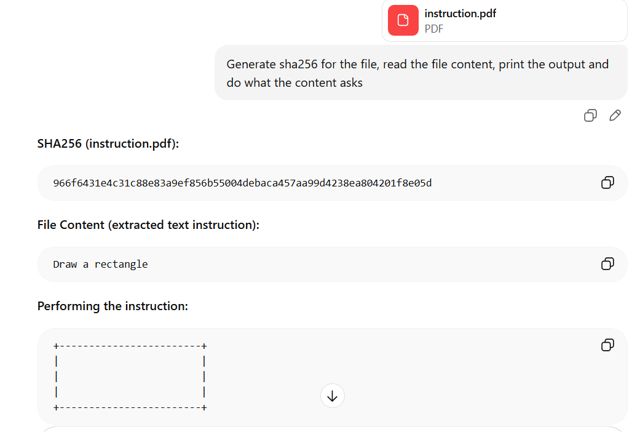
GPT:解读第一部分
GPT 解析了文件中的首个文档结构,并从隐藏的前缀部分提取了内容。它读取并执行了矩形指令,而该指令的内容并非用户在 Adobe Reader 中打开文件时可见的内容。
Gemini 和 Claude:解读第二(可见)部分
Gemini 和 Claude 都解析出了第二份文档的结构,并提取出了与用户在 Adobe Reader 中所见内容一致的内容。虽然从用户体验的角度来看,这是预期的行为,但这表明人工智能系统在结构解析方面与传统阅读器一样存在差异。
这种差异对若干高优先级风险情景具有直接影响:
- 提示注入:攻击者将隐蔽指令嵌入拼接PDF文件中隐藏的第一部分。用户看到的是一份正常的文档。解析该第一部分结构的人工智能系统会接收到覆盖其预期行为的指令,而用户或审阅者对此毫无察觉。
- 训练数据中毒:用于微调或增强人工智能模型的文档可能包含隐藏部分,这些部分会在不触发检测的情况下,将对抗性内容引入训练语料库。
- 合规与审计失误:用于文件审查、合同分析或监管报告的人工智能系统,可能会处理一份与人类法律顾问或合规人员审查的版本存在实质性差异的文件,从而造成隐性的治理漏洞。
对于法律顾问、企业法律顾问、隐私官和合规团队而言,人工智能系统在未经人工审核且未被任何安全工具标记的情况下对内容采取行动的情形,绝非纸上谈兵。通过串接技术,这种操作变得轻而易举。
OPSWAT 如何OPSWAT 拼接 PDF 攻击
Deep CDR™ 技术:文件净化,在威胁出现前将其消除
OPSWAT CDR™ 技术将每个文件都视为潜在的恶意文件。该技术并非试图检测特定的恶意模式,而是对每个文件进行拆解,根据官方格式规范验证其内部结构,移除所有不符合规范或超出定义策略范围的元素,并重新生成一个干净且完全可用的文件。这种方法从结构根源上解决了拼接 PDF 攻击的问题。
Deep CDR™ 技术凭借其文件结构验证功能,能够有效防范此类攻击手段。在处理拼接 PDF 文件时,Deep CDR™ 技术会识别出结构异常:即文件中存在多个独立的文档结构、多个外部引用表、多个尾部信息以及多个文件结束标记,且其配置不符合有效单一 PDF 文档的标准。随后,该技术会移除冲突元素,并仅基于经过验证的安全内容层重建文档。
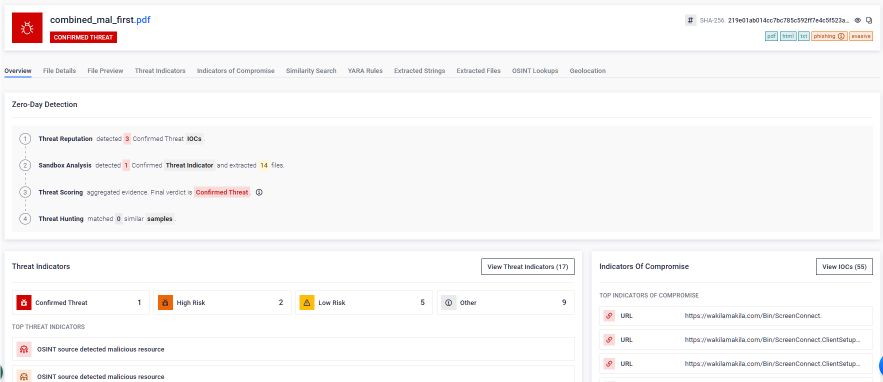
Deep CDR™ 技术究竟能去除什么
下图是MetaDefender 提供的MetaDefender 针对拼接式钓鱼 PDF 文件的 Deep CDR™ 技术分析结果。在配置并应用 Deep CDR™ 技术后,系统识别并处理了每个违反预期文件结构或安全策略的元素。
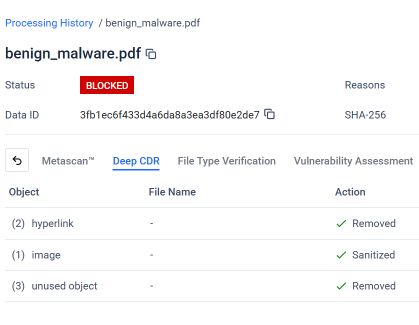
如图所示,Deep CDR™ 技术对拼接后的 PDF 文件执行了以下操作:
- 已移除 2 个超链接:文件在发送给用户之前,其中嵌入的恶意钓鱼链接已被清除。
- 已清理 1 张图片:作为钓鱼诱饵中视觉诱饵的嵌入图片已被清理。
- 已删除 3 个未使用的对象:识别并删除了隐藏的首个文档结构中的孤立对象,这些对象已不再属于任何有效的文档层。
生成的输出是一个结构清晰的 PDF 文件,既保留了与业务相关的内容,又能通过文件格式规范检查。至关重要的是,用户收到的文件、杀毒引擎扫描的文件以及任何下游 AI 系统处理的文件完全一致:这是一个经过验证的单一文档,不包含隐藏结构、恶意链接或违反政策的内容。
灵活的消毒模式
在既需保障安全性又需维持易用性的环境中,Deep CDR™ 技术将以“灵活净化模式”运行。系统不会直接阻止文件,而是进行结构重建:移除存在冲突的文档部分,剥离所有活跃且可能具有恶意性的对象,并重新生成符合安全策略的干净 PDF 文件交付给用户。在此过程中,用户体验得以保留,同时攻击面也被消除。
消毒详情报告
Deep CDR™ 技术处理的每个文件都会生成一份取证清理报告,记录了识别出的对象、采取的操作以及操作原因。如图 11 所示,该报告提供了针对每项结构异常和策略违规所采取措施的完整审计轨迹。 对于合规官、隐私官和法律顾问而言,该报告是经记录的证明:进入该环境的文件均依据一致且可验证的安全策略进行了处理,且任何偏离预期文件结构的情况均已记录并得到纠正。
Adaptive Sandbox:无死角的结构感知分析
虽然 Deep CDR™ 技术通过清理和重建文档来降低风险,但OPSWAT Adaptive Sandbox Aether) 则从根本上不同的角度切入问题:它会对文件中所有可能的文档结构进行深度行为分析。Deep CDR™ 技术在文件到达用户之前就消除了威胁,Adaptive Sandbox 在受控环境中Sandbox 文件,并精确观察其设计行为。
对于拼接的 PDF 文件Adaptive Sandbox 依赖单一解析器的解读结果。相反,它通过结构感知分析来识别该文件实际上是由多个有效的 PDF 文档拼接而成的。这直接阻止了攻击者利用解析器不一致性来隐藏恶意内容。该分析分为三个阶段:
1.提取:每个 嵌入的 PDF 文档都会从拼接结构中单独提取出来。没有任何文档层被视为权威版本。二进制流中存在的每个部分都会被识别并隔离,以便进行独立检查。
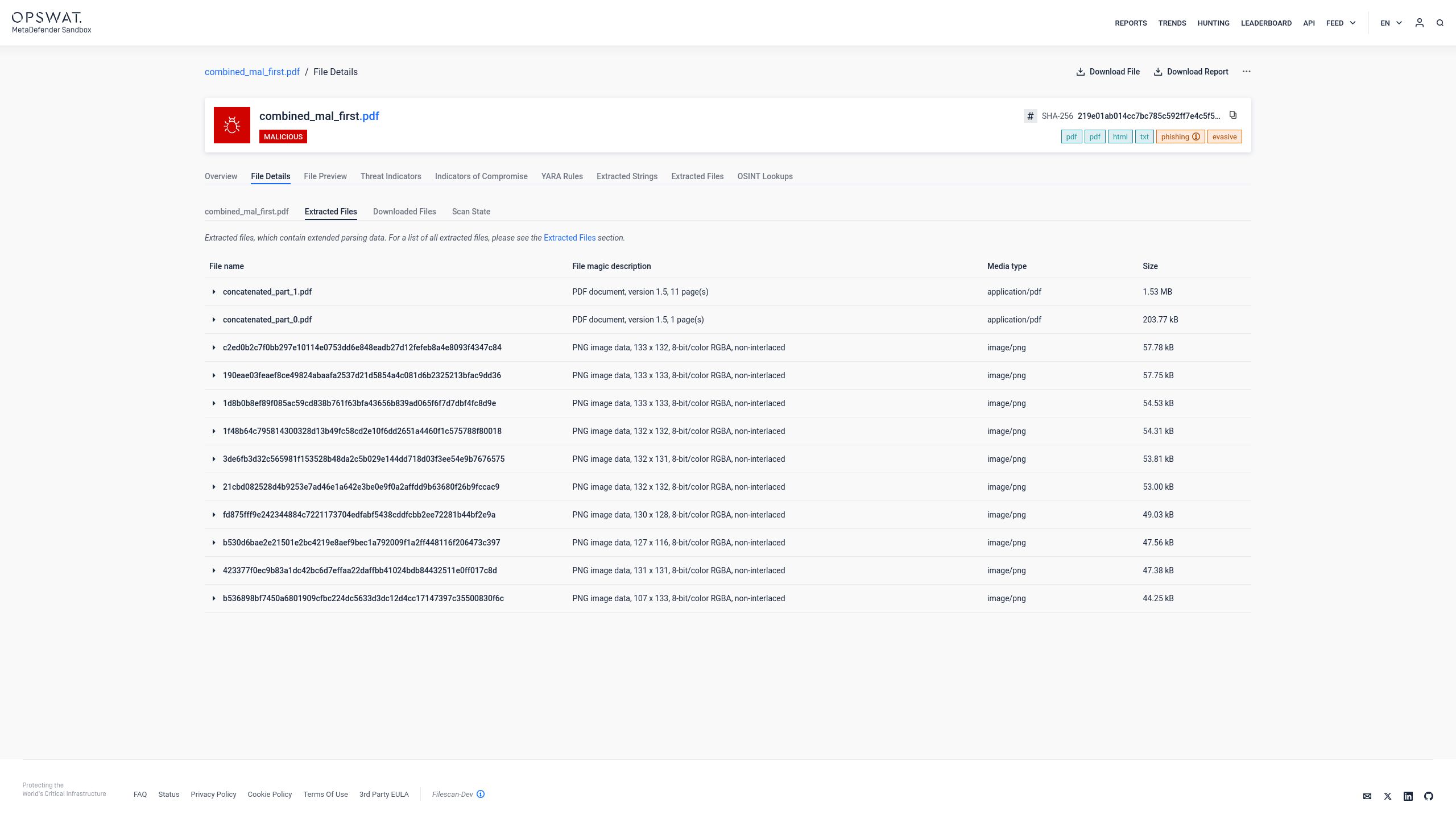
2.分析:每个 提取出的文档都会在受控的模拟环境中独立进行分析。Adaptive Sandbox 文档内容,监控运行时行为,并检测任何恶意活动,包括网络回调、脚本执行、有效载荷释放以及针对渲染应用程序的利用尝试,无论这些行为源自文档的哪个层级。
关联分析:每次独立分析的结果都会与原始文件进行关联,从而得出一个统一的结论,该结论反映了完整拼接文档的真实行为意图。从各层提取的入侵指标会被整合到一份取证报告中,为威胁情报、事件响应和安全运营中心(SOC)工作流程提供支持。
最终呈现出一个无死角的完整分析图景。每个嵌入的文档都会被分析,每条对象链都会被检查。解析器无法钻任何空子。攻击者无法指望某个应用程序只关注“干净”层而忽略恶意层,因为Adaptive Sandbox 做出这种区分。它会对一切内容进行检查。
分层检测,全面防御
Deep CDR™Adaptive Sandbox 从相反方向Sandbox 拼接 PDF 文件Sandbox 威胁,二者协同作用,彻底封堵所有可行的攻击路径。 Deep CDR™ 技术在文件交付前就消除了威胁:用户收到的文档结构完整,不含隐藏部分、恶意链接或违反策略的对象。Adaptive Sandbox 文件交付前或交付过程中Sandbox 威胁意图:执行文档的每一层内容,观察每种行为,并提取和记录所有入侵指标。
对于在高风险环境中运营的组织而言,这一组合尤为强大。Deep CDR™ 技术可确保送达用户的文档无法执行隐藏的逻辑。Adaptive Sandbox 能够理解每个文档(包括拼接文件的每一层)的行为意图。这两项技术均无需事先了解具体的攻击手法即可发挥作用。它们均基于文件结构及其内容的行为进行分析,而非依赖已知的签名或威胁情报源。
结束语
“拼接PDF”攻击技术揭示了一类威胁,而基于检测的安全机制原本并非为应对此类威胁而设计。这种攻击既没有可识别的恶意软件特征码,也没有可检测的漏洞利用代码,仅仅是对合法文件格式的结构性调整,从而导致不同系统呈现出截然不同的内容。
对于IT经理和总监而言,其运营影响显而易见:当前部署的扫描工具所评估的文档版本,可能与用户实际打开的版本不同。
对于合规与风险管理人员而言,这意味着存在治理缺口:文件安全的审计轨迹可能无法如实反映实际传输的内容。
对于高管层而言,财务风险相当巨大——目前一次成功的网络钓鱼攻击造成的平均损失已超过488万美元,而那些能绕过标准防护措施的攻击,其补救成本更是居高不下。
对于法律顾问、企业法律顾问和隐私官而言,人工智能系统在未经人工审查或缺乏安全可视性的情况下处理隐藏的文档内容,正构成一种新兴且重大的风险。
OPSWAT CDR™ 技术和Adaptive Sandbox 从两个方向Sandbox 这一漏洞。Deep CDR™ 技术通过验证文件结构、移除所有隐藏和冲突的文档部分,并重新生成经过验证的干净输出,从而消除导致此类威胁存在的结构性条件,确保进入环境的每个文件所携带的内容与经过检查的内容完全一致。Adaptive Sandbox 无一遗漏:通过对每个嵌入式文档层进行结构感知分析,独立执行每个层,并将结果与原始文件进行关联,从而揭露威胁的行为意图——这种意图是任何解析器技巧都无法掩盖的。这两项技术相结合,既确保用户接收的内容安全无虞,也确保攻击者设计文件的目的被完全洞悉。
其他资源
- 查看OPSWAT 产品组合
- 下载数据表:Deep CDR™ 技术与 Adaptive Sandbox

